Anda mungkin juga menyukai
- Makalah Data Mining PDFDokumen16 halamanMakalah Data Mining PDFhanang setyaBelum ada peringkat
- 11-Diagram Tabel KeputusanDokumen22 halaman11-Diagram Tabel KeputusanAvenueeBelum ada peringkat
- Buku 1 Pengertian Dasar 2016Dokumen99 halamanBuku 1 Pengertian Dasar 2016Kanasha HumairaBelum ada peringkat
- (Compiled) Kopi Stater Uas SMT 5Dokumen154 halaman(Compiled) Kopi Stater Uas SMT 5Bella Zaalii (Bella Reffanda H)Belum ada peringkat
- SISTEM KEHADIRANDokumen7 halamanSISTEM KEHADIRANfitri prastiwiBelum ada peringkat
- Tugas Data MiningDokumen2 halamanTugas Data MiningImbranBelum ada peringkat
- PENGENALAN POLADokumen3 halamanPENGENALAN POLAFajar WicaksonoBelum ada peringkat
- METODE LINEAR PROGRAMMING TerbaruDokumen29 halamanMETODE LINEAR PROGRAMMING TerbaruBintang Ban JombangBelum ada peringkat
- Statistika Analisis Ukuran Penyebaran Data (Kemiringan Dan Kruncingan) "Data Angka Anak Tidak Sekolah Dibeberapa Provinsi"Dokumen17 halamanStatistika Analisis Ukuran Penyebaran Data (Kemiringan Dan Kruncingan) "Data Angka Anak Tidak Sekolah Dibeberapa Provinsi"Lilyss RoswythaBelum ada peringkat
- Acuan Perbandingan ID3 Dan C4.5Dokumen7 halamanAcuan Perbandingan ID3 Dan C4.5Yudhi Pratama TanjungBelum ada peringkat
- Manfaat Dan Jenis Penyajian DataDokumen32 halamanManfaat Dan Jenis Penyajian DataVirly Gusviyani Part IIBelum ada peringkat
- Analisa Sistem Informasi Rumah SakitDokumen28 halamanAnalisa Sistem Informasi Rumah SakitAnggoro Tri PutrantoBelum ada peringkat
- Statistika Deskriptif Latihan Uts Semester 2 Part2Dokumen30 halamanStatistika Deskriptif Latihan Uts Semester 2 Part2Imam Arif100% (1)
- Tugas 2Dokumen7 halamanTugas 2alfariantoBelum ada peringkat
- Kriptografi Klasik (2021)Dokumen73 halamanKriptografi Klasik (2021)Fachril FahrilBelum ada peringkat
- Buku - 1 MatriksDokumen192 halamanBuku - 1 MatriksfrancisBelum ada peringkat
- Pertemuan 9 Larik Atau ArrayDokumen16 halamanPertemuan 9 Larik Atau Arrayjonny45659Belum ada peringkat
- DISTRIBUSI FREKUENSIDokumen15 halamanDISTRIBUSI FREKUENSIjabolbolBelum ada peringkat
- Laporan Kegiatan Prakerin HanieDokumen22 halamanLaporan Kegiatan Prakerin HanieStephanie HawaBelum ada peringkat
- Soal Uas 17-12-2020-1Dokumen2 halamanSoal Uas 17-12-2020-1Moch Ramadhan JatikusworoBelum ada peringkat
- Kamus Data Dokumen MasukanDokumen6 halamanKamus Data Dokumen MasukanWidia NingrumBelum ada peringkat
- Business Plan Part 1Dokumen20 halamanBusiness Plan Part 1Sofyan AlvianBelum ada peringkat
- Algoritma K-Nearest Neighbor (K-NN)Dokumen10 halamanAlgoritma K-Nearest Neighbor (K-NN)candraBelum ada peringkat
- Makalah Kelompok 1 - Statistika Ekonomi Dan BisnisDokumen16 halamanMakalah Kelompok 1 - Statistika Ekonomi Dan BisnisRizal AmboBelum ada peringkat
- UTS StatistikaDokumen8 halamanUTS StatistikaANDINI SartikaBelum ada peringkat
- Contoh Makalah Sistem Informasi ManajemenDokumen7 halamanContoh Makalah Sistem Informasi ManajemenVisi HapdiastoroBelum ada peringkat
- 1 Pengantar Analitika DataDokumen37 halaman1 Pengantar Analitika Data21-A-1-22 Alfonsius LintangBelum ada peringkat
- PHP dan DatabaseDokumen15 halamanPHP dan DatabaseShin ZBelum ada peringkat
- Statistika SoalDokumen3 halamanStatistika SoalTri Candra PutraBelum ada peringkat
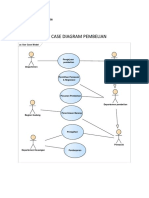
- Use Case Dan Sequence, Activity Diagram Pembelian Tugas Muhamad SibliDokumen3 halamanUse Case Dan Sequence, Activity Diagram Pembelian Tugas Muhamad SibliYanto PlesiBelum ada peringkat
- Tugas Kelompok ImkDokumen15 halamanTugas Kelompok ImkIlham Maulana sidiqBelum ada peringkat
- Pertemuan 1 (Riset Operasional)Dokumen91 halamanPertemuan 1 (Riset Operasional)Julius GunawanBelum ada peringkat
- Pertemuan 3 Statistik EkonomiDokumen14 halamanPertemuan 3 Statistik EkonomiNgizatul AfifahBelum ada peringkat
- LTM Statistika OkDokumen54 halamanLTM Statistika OkRhani JayantiBelum ada peringkat
- Proposal Sosialisasi Internet Sehat Di Kalangan Remaja Untuk Meminimalkan Dampak Negatif Dari BerinternetDokumen7 halamanProposal Sosialisasi Internet Sehat Di Kalangan Remaja Untuk Meminimalkan Dampak Negatif Dari BerinternetMuhammad Raihan AzzikriBelum ada peringkat
- ANALISIS DISKRIMINAN PT HATCODokumen28 halamanANALISIS DISKRIMINAN PT HATCONisfi Hemas D AsmaraBelum ada peringkat
- Kelompok 24 - Makalah Data Mining - Preprocessing DataDokumen13 halamanKelompok 24 - Makalah Data Mining - Preprocessing DataAdinda Nur HalisyahBelum ada peringkat
- Curriculum Vitae (CV) : Calon Peserta Program Kampus Merdeka Di Bank IndonesiaDokumen3 halamanCurriculum Vitae (CV) : Calon Peserta Program Kampus Merdeka Di Bank IndonesianianiaBelum ada peringkat
- UntitledDokumen11 halamanUntitledAzzahra AllyshaBelum ada peringkat
- Proposal Ham 1Dokumen11 halamanProposal Ham 1Alexandra Indriyanti0% (1)
- Analisa Data Berkala dengan Metode Least SquareDokumen23 halamanAnalisa Data Berkala dengan Metode Least SquareMega ListianaBelum ada peringkat
- Pertemuan I Riset OperasionalDokumen31 halamanPertemuan I Riset OperasionalYuwarna DewiBelum ada peringkat
- Data Mining WalmartDokumen5 halamanData Mining WalmartRidwan HsBelum ada peringkat
- Statistika Deskriptif Latihan Uts Semester 2Dokumen1 halamanStatistika Deskriptif Latihan Uts Semester 2Imam ArifBelum ada peringkat
- TabelDistribusiFrekuensiDokumen11 halamanTabelDistribusiFrekuensiGamal KelanaBelum ada peringkat
- Proposal ClusteringDokumen8 halamanProposal ClusteringMuhammad YunusBelum ada peringkat
- Latihan Praktikum Ms-ExcelDokumen127 halamanLatihan Praktikum Ms-Excelkhairipahlevi0% (1)
- SISTEM PENDATAAN PRESTASIDokumen33 halamanSISTEM PENDATAAN PRESTASIMade KresnaBelum ada peringkat
- RSMSJRPDokumen1 halamanRSMSJRPSuwandy LieBelum ada peringkat
- Tugas Makalah Statistika Pariwisata NiaDokumen14 halamanTugas Makalah Statistika Pariwisata NiaAli Abdul Basir0% (1)
- Proposal Data Mining M Ilham Effendi (Stikom DB Jambi) 2019Dokumen23 halamanProposal Data Mining M Ilham Effendi (Stikom DB Jambi) 2019ILham EffendiiiBelum ada peringkat
- REGRESI LINIERDokumen21 halamanREGRESI LINIERMuhammadRidhoIryanandaBelum ada peringkat
- SOAL UAS StatistikaDokumen2 halamanSOAL UAS StatistikaLaurensia Dhika MaretasaniBelum ada peringkat
- Makalah Riset Operasi Kel.1Dokumen32 halamanMakalah Riset Operasi Kel.1Rosita 00Belum ada peringkat
- Analisis Algoritma Sequential Search Dan Binary Search Pada Big DataDokumen6 halamanAnalisis Algoritma Sequential Search Dan Binary Search Pada Big DataYoga ReligiaBelum ada peringkat
- Modul Stat - Ekonomi 2019Dokumen27 halamanModul Stat - Ekonomi 2019Rifki MaulanaBelum ada peringkat
- Perancangan Sistem Informasi Media Promosi Dan Penjualan Kerajinan Tangan Sulaman Masyarakat Naras Kota Pariaman (1) - DikonversiDokumen124 halamanPerancangan Sistem Informasi Media Promosi Dan Penjualan Kerajinan Tangan Sulaman Masyarakat Naras Kota Pariaman (1) - Dikonversibintang felinBelum ada peringkat
- Makalah Data MiningDokumen13 halamanMakalah Data MiningSujana Aris Krisnawan67% (3)
- DATA MININGDokumen16 halamanDATA MININGmnight494Belum ada peringkat
- Data MiningDokumen13 halamanData MiningWisnu Dwi CahyaBelum ada peringkat