Anda mungkin juga menyukai
- Analisis RegresiDokumen12 halamanAnalisis RegresiYossi OliviaBelum ada peringkat
- Analisis Regresi & KorelasiDokumen24 halamanAnalisis Regresi & KorelasiNanda DwiBelum ada peringkat
- Regresi Parametrik Dan Non-ParametrikDokumen16 halamanRegresi Parametrik Dan Non-Parametrikberto windi100% (3)
- REGRESI MANUALDokumen14 halamanREGRESI MANUALPetronella Mira MelatiBelum ada peringkat
- REGRESI POLINOMIALDokumen15 halamanREGRESI POLINOMIALFifth AnalistBelum ada peringkat
- 63 124 2 PBDokumen8 halaman63 124 2 PBLizanuraidaBelum ada peringkat
- Analisis RegresiDokumen13 halamanAnalisis RegresiAnto Asrianto0% (1)
- 2 - Analisis RegresiDokumen24 halaman2 - Analisis RegresiHandikaBelum ada peringkat
- 13.3-13.4 + Latihan Soal StatmatDokumen7 halaman13.3-13.4 + Latihan Soal StatmatAZZAHRA SHINTA BILQIS NURFATABelum ada peringkat
- MATER 3 MODEL REGRESi DUA VARiABEL PERSOALAN PERKiRAAN (ESTiMASi) - OKDokumen13 halamanMATER 3 MODEL REGRESi DUA VARiABEL PERSOALAN PERKiRAAN (ESTiMASi) - OKnazipawatiBelum ada peringkat
- Metode Kuadrat TerkecilDokumen11 halamanMetode Kuadrat TerkecilRian JuliantoBelum ada peringkat
- F. Regresi LinearDokumen10 halamanF. Regresi LinearifaBelum ada peringkat
- Kelompok 10 - Makalah Regresi Dan KorelasiDokumen14 halamanKelompok 10 - Makalah Regresi Dan KorelasiSitiJenab UlapiahBelum ada peringkat
- Analisis Regresi Dan KorelasiDokumen6 halamanAnalisis Regresi Dan Korelasipendulum kotamobaguBelum ada peringkat
- Materi Regresi Linear BergandaDokumen12 halamanMateri Regresi Linear BergandaLindianiBelum ada peringkat
- Nurazizah MahdinDokumen5 halamanNurazizah Mahdincici safitriBelum ada peringkat
- Bab X Analisis Regeresi BergandaDokumen23 halamanBab X Analisis Regeresi BergandaRamdani SariBelum ada peringkat
- Analisis Regresi & Korelasi BergandaDokumen11 halamanAnalisis Regresi & Korelasi BergandaSISWANTO SISBelum ada peringkat
- REGRESI DAN KORELASIDokumen17 halamanREGRESI DAN KORELASIGlenn Gilbert BilldrianusBelum ada peringkat
- OLS-REGRESIDokumen9 halamanOLS-REGRESIAzriel ArmandaBelum ada peringkat
- 1mmt216 RegresiDokumen16 halaman1mmt216 RegresiMuhammadur rezaBelum ada peringkat
- 02 LinearitasDokumen29 halaman02 LinearitasDaryusmanBelum ada peringkat
- Soal 6 YaDokumen114 halamanSoal 6 YaYasmin PebrianiBelum ada peringkat
- Kelompok 1 - Variansi Dan Simpangan BakuDokumen13 halamanKelompok 1 - Variansi Dan Simpangan BakuWynarnie JHBelum ada peringkat
- Regresi Linier SederhanaDokumen12 halamanRegresi Linier SederhanaVardy FahrizalBelum ada peringkat
- Teori Sampel - Perbandingan Perkiraan RasioDokumen6 halamanTeori Sampel - Perbandingan Perkiraan RasiohaedaeeBelum ada peringkat
- REGRESI LINEARDokumen14 halamanREGRESI LINEARJovelia KojongianBelum ada peringkat
- Regression Example - Geo-Electric Method - ResistDokumen33 halamanRegression Example - Geo-Electric Method - ResistIL YA SBelum ada peringkat
- Pertemuan4 Ada RobustDokumen77 halamanPertemuan4 Ada RobustAzuza AnessutasiyaBelum ada peringkat
- Analisis Regresi Terapan S2 STT - 2019Dokumen33 halamanAnalisis Regresi Terapan S2 STT - 2019miftahul jannahBelum ada peringkat
- BAB VIII KORELASI & REGRESIDokumen5 halamanBAB VIII KORELASI & REGRESIkusumahadieaBelum ada peringkat
- Sri Vanny SaragihDokumen15 halamanSri Vanny Saragihvalent tralalaBelum ada peringkat
- Beberapa Distribusi Peluang KontinuDokumen60 halamanBeberapa Distribusi Peluang KontinuAgus KristiyonoBelum ada peringkat
- INTEGRAL TENTU UNTUK FUNGSI BERBAGAI BENTUKDokumen10 halamanINTEGRAL TENTU UNTUK FUNGSI BERBAGAI BENTUKAhmad AlfinBelum ada peringkat
- Regresi Linear Dan Metode GrafikDokumen20 halamanRegresi Linear Dan Metode GrafikMargono SoplantilaBelum ada peringkat
- BAB II RegresiDokumen8 halamanBAB II Regresiirwan berryBelum ada peringkat
- Analisis Regresi dan PencilanDokumen8 halamanAnalisis Regresi dan PencilanAlriski KurniawanBelum ada peringkat
- Bahan Kasus Curve Fitting Dan Interpolasi Doc DyDokumen16 halamanBahan Kasus Curve Fitting Dan Interpolasi Doc Dydarnia anitaBelum ada peringkat
- REGMULTIDokumen18 halamanREGMULTIAlya NabilahBelum ada peringkat
- Tugas Pertemuan 7Dokumen5 halamanTugas Pertemuan 7Titis AndriawanBelum ada peringkat
- Bab 9 - Transformasi GeometriDokumen25 halamanBab 9 - Transformasi GeometriArifiantoBelum ada peringkat
- Makalah Analisis Regresi Linier BergandaDokumen18 halamanMakalah Analisis Regresi Linier BergandaSutriana Dina Uli ManurungBelum ada peringkat
- REGRESI DAN KORELASIDokumen9 halamanREGRESI DAN KORELASIK18Mohamad Masrur FatkhurroziTSBelum ada peringkat
- Pendugaan Parameter StatistikDokumen11 halamanPendugaan Parameter StatistikRaden taufik CandrawinataBelum ada peringkat
- Ringkasan Rumus Analisis Regresi HdestinaDokumen3 halamanRingkasan Rumus Analisis Regresi Hdestinahennyazalea9434Belum ada peringkat
- 92 182 2 PBDokumen9 halaman92 182 2 PBjahro haniBelum ada peringkat
- Kuliah #9 Statistik I - Analisis Korelasi SederhanaDokumen28 halamanKuliah #9 Statistik I - Analisis Korelasi SederhanaSinta meirelaBelum ada peringkat
- Pertemuan 6 Transformasi FourierDokumen51 halamanPertemuan 6 Transformasi FourierAji Siie Budag SpendupatBelum ada peringkat
- Makalah Matematika EksponenDokumen3 halamanMakalah Matematika EksponenYumni Alfiah RihadatulaisyBelum ada peringkat
- LinearitasDokumen22 halamanLinearitasnathanbarayBelum ada peringkat
- OPTIMIZED CURVE FITTINGDokumen49 halamanOPTIMIZED CURVE FITTINGAdriansyah WillyBelum ada peringkat
- GLS Estimasi KelayakanDokumen7 halamanGLS Estimasi KelayakanDaniyah나다Belum ada peringkat
- Analisis RegresiDokumen7 halamanAnalisis RegresiHafizh Al-jauharBelum ada peringkat
- Elastisitas dan PlastisitasDokumen39 halamanElastisitas dan PlastisitasYuda NugrahaBelum ada peringkat
- Kertas 1 (Paper 1) Matematik Tambahan (Additional Mathematics) 2022 Johor Set 2 Soalan PercubaanDokumen24 halamanKertas 1 (Paper 1) Matematik Tambahan (Additional Mathematics) 2022 Johor Set 2 Soalan PercubaanmuhammadhakimshamsulanuarBelum ada peringkat
- Rangkuman Tema 9 Kelas V SDDokumen7 halamanRangkuman Tema 9 Kelas V SDLa Nina Gunaswara SamuderaBelum ada peringkat
- SOAL MATEMATIKA KELAS 5 SD RanyaDokumen2 halamanSOAL MATEMATIKA KELAS 5 SD RanyaLa Nina Gunaswara SamuderaBelum ada peringkat
- Rangkuman Tema 9 Kelas V SDDokumen7 halamanRangkuman Tema 9 Kelas V SDLa Nina Gunaswara SamuderaBelum ada peringkat
- Rangkuman UASDokumen9 halamanRangkuman UASLa Nina Gunaswara SamuderaBelum ada peringkat
- SOAL MATEMATIKA KELAS 5 SD RanyaDokumen2 halamanSOAL MATEMATIKA KELAS 5 SD RanyaLa Nina Gunaswara SamuderaBelum ada peringkat
- PASDokumen4 halamanPASLa Nina Gunaswara SamuderaBelum ada peringkat
- Analisis MultivariatDokumen124 halamanAnalisis MultivariatLa Nina Gunaswara SamuderaBelum ada peringkat
- Eksplanasi Kelas 5 SDDokumen4 halamanEksplanasi Kelas 5 SDLa Nina Gunaswara SamuderaBelum ada peringkat
- Rangkuman Day 8Dokumen50 halamanRangkuman Day 8La Nina Gunaswara SamuderaBelum ada peringkat
- Tugas IbprDokumen4 halamanTugas IbprLa Nina Gunaswara SamuderaBelum ada peringkat
- Rangkuman UASDokumen9 halamanRangkuman UASLa Nina Gunaswara SamuderaBelum ada peringkat
- SOALDokumen4 halamanSOALTony Nofariandy67% (3)
- Soal Latihan Debit 5 SDDokumen1 halamanSoal Latihan Debit 5 SDLa Nina Gunaswara SamuderaBelum ada peringkat
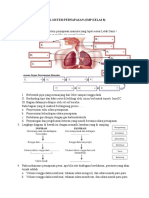
- Sistem Pernapasan SMPDokumen7 halamanSistem Pernapasan SMPLa Nina Gunaswara SamuderaBelum ada peringkat
- PASDokumen4 halamanPASLa Nina Gunaswara SamuderaBelum ada peringkat
- Berikut jawaban untuk soal tersebut:1. d2. d3. a 4. c5. b6. b7. bDokumen9 halamanBerikut jawaban untuk soal tersebut:1. d2. d3. a 4. c5. b6. b7. bLa Nina Gunaswara SamuderaBelum ada peringkat
- Zooplankton Dan LamunDokumen11 halamanZooplankton Dan LamunLa Nina Gunaswara SamuderaBelum ada peringkat
- JENISDokumen1 halamanJENISLa Nina Gunaswara SamuderaBelum ada peringkat
- Soal Bindo Tema 6Dokumen4 halamanSoal Bindo Tema 6La Nina Gunaswara SamuderaBelum ada peringkat
- PENCERNAAN SAPIDokumen4 halamanPENCERNAAN SAPILa Nina Gunaswara SamuderaBelum ada peringkat
- Tugas II MarbioDokumen5 halamanTugas II MarbioLa Nina Gunaswara SamuderaBelum ada peringkat
- Persamaan Dan Perbedaan Sistem Pencernaan Manusia Dan SapiDokumen1 halamanPersamaan Dan Perbedaan Sistem Pencernaan Manusia Dan SapiLa Nina Gunaswara SamuderaBelum ada peringkat
- Soal Pecahan RanyaDokumen8 halamanSoal Pecahan RanyaLa Nina Gunaswara SamuderaBelum ada peringkat
- Teks EksplanasiDokumen1 halamanTeks EksplanasiLa Nina Gunaswara SamuderaBelum ada peringkat
- Berikut jawaban untuk soal tersebut:1. d2. d3. a 4. c5. b6. b7. bDokumen9 halamanBerikut jawaban untuk soal tersebut:1. d2. d3. a 4. c5. b6. b7. bLa Nina Gunaswara SamuderaBelum ada peringkat
- Soal MatematikaDokumen2 halamanSoal MatematikaLa Nina Gunaswara SamuderaBelum ada peringkat
- Pulau Di IndonesiaDokumen2 halamanPulau Di IndonesiaLa Nina Gunaswara SamuderaBelum ada peringkat
- Buku Ajar Banjir RobDokumen10 halamanBuku Ajar Banjir RobLa Nina Gunaswara SamuderaBelum ada peringkat
- PantunDokumen2 halamanPantunLa Nina Gunaswara SamuderaBelum ada peringkat