Anda mungkin juga menyukai
- Soal 4 Sistem BerkasDokumen13 halamanSoal 4 Sistem BerkasAnonymous bjcDNYEiBelum ada peringkat
- TUGAS 04 (Makalah Organisasi Berkas Indexed Sequential)Dokumen14 halamanTUGAS 04 (Makalah Organisasi Berkas Indexed Sequential)fajarBelum ada peringkat
- Review Jurnal Struktur DataDokumen5 halamanReview Jurnal Struktur DataEtti Puspita50% (2)
- Breadth First Searching Dan Contoh Coding BFSDokumen6 halamanBreadth First Searching Dan Contoh Coding BFSNadya Chitayae0% (1)
- Pertemuan 3: Array Dimensi BanyakDokumen17 halamanPertemuan 3: Array Dimensi BanyakMuhammad Raihan TamamBelum ada peringkat
- Pengertian ALU Beserta Fungsi Dan Rangkaian ALU Pada CPUDokumen7 halamanPengertian ALU Beserta Fungsi Dan Rangkaian ALU Pada CPUhenryprasetyoBelum ada peringkat
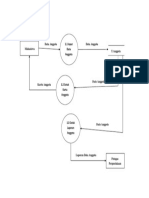
- DFD Level 2 Proses Pendaftaran Anggota PerpustakaanDokumen1 halamanDFD Level 2 Proses Pendaftaran Anggota PerpustakaanDanang SutejoBelum ada peringkat
- Materi Constructor Dan Encapsulasi PythonDokumen7 halamanMateri Constructor Dan Encapsulasi PythonRini RcrBelum ada peringkat
- Sequence DiagramDokumen3 halamanSequence Diagramsasmito skomBelum ada peringkat
- Laporan Hasil Mod 3Dokumen15 halamanLaporan Hasil Mod 3Kristina LorenzaBelum ada peringkat
- Rangkuman Aljabar RelasionalDokumen7 halamanRangkuman Aljabar RelasionalSelly Handik PratiwiBelum ada peringkat
- Tugas Organisasi Berkas RelatifDokumen10 halamanTugas Organisasi Berkas RelatifWandyBelum ada peringkat
- Array Dimensi 1 Dan 2Dokumen24 halamanArray Dimensi 1 Dan 2silviaBelum ada peringkat
- Algoritma Dan Struktur Data 1 2Dokumen77 halamanAlgoritma Dan Struktur Data 1 2Devv Lare OsèngBelum ada peringkat
- Laporan Alpro 3 Modul 3 AndriDokumen19 halamanLaporan Alpro 3 Modul 3 AndriAndriantoBelum ada peringkat
- Laporan Praktikum Sistem Basis Data Modul 8Dokumen38 halamanLaporan Praktikum Sistem Basis Data Modul 8Muhammad RidwanBelum ada peringkat
- Tipe Data BentukanDokumen3 halamanTipe Data BentukanrijalBelum ada peringkat
- Handout INF202 INF202 Struktur Data Wayan Pertemuan 13 14Dokumen30 halamanHandout INF202 INF202 Struktur Data Wayan Pertemuan 13 14Mahendra putra RaharjaBelum ada peringkat
- SI-11 QUIS UTS Pertemuan 8 PBDDokumen4 halamanSI-11 QUIS UTS Pertemuan 8 PBDshirogam100% (2)
- Makalah Struktur DataDokumen13 halamanMakalah Struktur DataAtdhyctive Ga GaBelum ada peringkat
- Uml Sistem Informasi Rumah SakitDokumen2 halamanUml Sistem Informasi Rumah Sakitemo0% (1)
- Jbptunikompp GDL Achmadfach 18960 4 Kuliah1 2Dokumen19 halamanJbptunikompp GDL Achmadfach 18960 4 Kuliah1 2Nunung MardiahBelum ada peringkat
- Pert 3 - Manage Tables PDFDokumen10 halamanPert 3 - Manage Tables PDFCindyBelum ada peringkat
- Latihan Dasar PythonDokumen12 halamanLatihan Dasar Pythonsakina kinaBelum ada peringkat
- ErdDokumen18 halamanErdRidwan EffendiBelum ada peringkat
- Pertemuan 10 - Aljabar RelasionalDokumen27 halamanPertemuan 10 - Aljabar RelasionalVian AlfalahBelum ada peringkat
- Penerapan Stack Menggunakan Bahasa Pemrograman C++Dokumen20 halamanPenerapan Stack Menggunakan Bahasa Pemrograman C++Angga PrihadieBelum ada peringkat
- TPL0132 - 12 - Nilai Eigen Dan Nilai VektorDokumen11 halamanTPL0132 - 12 - Nilai Eigen Dan Nilai VektorAnggita DayaniBelum ada peringkat
- QUIZ Struktur Data C++ (KENT)Dokumen2 halamanQUIZ Struktur Data C++ (KENT)Mauludin AhmadBelum ada peringkat
- ERD DFD Kamus DataDokumen59 halamanERD DFD Kamus DataazureiceBelum ada peringkat
- Algoritma Sequential SearchDokumen18 halamanAlgoritma Sequential SearchTrafalgar S TopanBelum ada peringkat
- Laporan Hasil Praktikum Struktur DataDokumen22 halamanLaporan Hasil Praktikum Struktur DataIrwandi IrwanBelum ada peringkat
- Soal AluDokumen1 halamanSoal Aluhadi priyonoBelum ada peringkat
- Menjelaskan Beberapa Istilah Atau Metode Atau Fungsi Yang Berkaitan Dengan ArrayDokumen1 halamanMenjelaskan Beberapa Istilah Atau Metode Atau Fungsi Yang Berkaitan Dengan ArrayAnis PratiwiBelum ada peringkat
- Modul Alg Sdat 1Dokumen41 halamanModul Alg Sdat 1Kim Sains50% (2)
- Hasil Praktikum Struktur Data IDokumen17 halamanHasil Praktikum Struktur Data IAdin FahruddinBelum ada peringkat
- Perkondisian C++Dokumen21 halamanPerkondisian C++takumiBelum ada peringkat
- Contoh Database Normalisasi Toko BangunanDokumen4 halamanContoh Database Normalisasi Toko BangunanariesBelum ada peringkat
- Laporan Praktikum Rekursif 1Dokumen5 halamanLaporan Praktikum Rekursif 1Rafiq MuzakkiBelum ada peringkat
- Arithmetic Logic UnitDokumen15 halamanArithmetic Logic UnitAriez CapriBoyBelum ada peringkat
- Binary Tree Pada JavaDokumen13 halamanBinary Tree Pada JavaCindy FatikhaBelum ada peringkat
- Sorting & Searching 1Dokumen14 halamanSorting & Searching 1Rifqi MaulaturBelum ada peringkat
- Database Dengan APOTIK SSC PDFDokumen2 halamanDatabase Dengan APOTIK SSC PDFSuwandono MustDont100% (1)
- Pratikum AlgoritmaDokumen34 halamanPratikum AlgoritmaNeVhaa VhaBelum ada peringkat
- Pertemuan 9 STDDokumen2 halamanPertemuan 9 STDAkbar Falladika0% (1)
- Dhea Kristina - Laporan Hasil Praktikum Modul IIIDokumen25 halamanDhea Kristina - Laporan Hasil Praktikum Modul IIIDheaBelum ada peringkat
- Representasi DataDokumen19 halamanRepresentasi Databeny setiadiBelum ada peringkat
- Soal Latihan Bahasa Dan Automata Mesin PdaDokumen4 halamanSoal Latihan Bahasa Dan Automata Mesin PdaFahrul RozyBelum ada peringkat
- HIMPUNANDokumen29 halamanHIMPUNANAl FandhyBelum ada peringkat
- Laporan Praktikum 3Dokumen6 halamanLaporan Praktikum 3AKHMAD ZUHDYBelum ada peringkat
- Laporan Praktikum Pemrograman Dasar Unit 9 - MEMBUAT FUNGSI SENDIRIDokumen15 halamanLaporan Praktikum Pemrograman Dasar Unit 9 - MEMBUAT FUNGSI SENDIRINAUFAL R ARYAPUTRA ARYAPUTRABelum ada peringkat
- Linked ListDokumen3 halamanLinked ListFxHartantoBelum ada peringkat
- Laporan Hasil Praktikum Mod 5Dokumen22 halamanLaporan Hasil Praktikum Mod 5Ruben SucionoBelum ada peringkat
- Pertemuan 9: Queue (Antrean)Dokumen21 halamanPertemuan 9: Queue (Antrean)Faiq AlhimmahBelum ada peringkat
- Normalisasi Data PDFDokumen64 halamanNormalisasi Data PDFchoirunissaBelum ada peringkat
- P13 Statistika - Praktik Regresi 1 ExcelDokumen18 halamanP13 Statistika - Praktik Regresi 1 ExcelM Devid Irawan XII BDP 1Belum ada peringkat
- Kumpulan Soal Uts Metode Statistika Stk2Dokumen18 halamanKumpulan Soal Uts Metode Statistika Stk2Intan WidyawatiBelum ada peringkat
- Organisasi Berkas Indeks SequentialDokumen11 halamanOrganisasi Berkas Indeks SequentialAndika Yusuf HidayatBelum ada peringkat
- Tugas 4 Sistem BerkasDokumen18 halamanTugas 4 Sistem BerkasarrumBelum ada peringkat
- Tugas 4 Sistem Berkas Organisasi Berkas Indexed SequentialDokumen11 halamanTugas 4 Sistem Berkas Organisasi Berkas Indexed SequentialdiniBelum ada peringkat
- PPT KimiaDokumen13 halamanPPT KimiaFathur Rahman FauzanBelum ada peringkat
- TUGAS Pak Ahmad StackDokumen7 halamanTUGAS Pak Ahmad StackFathur Rahman FauzanBelum ada peringkat
- SQLDokumen15 halamanSQLDhiyaa ElhaqBelum ada peringkat
- Media Penyimpanan DataDokumen46 halamanMedia Penyimpanan DataFathur Rahman Fauzan100% (1)
- Media PenyimpananDokumen31 halamanMedia PenyimpananarifinznBelum ada peringkat
- SISTEM BERKAS Media PenyimpananDokumen22 halamanSISTEM BERKAS Media PenyimpananFathur Rahman FauzanBelum ada peringkat
- Tugas VB - Listview PDFDokumen3 halamanTugas VB - Listview PDFFathur Rahman FauzanBelum ada peringkat
- PPT KimiaDokumen13 halamanPPT KimiaFathur Rahman FauzanBelum ada peringkat
- Soal Dinamika Peran Indonesia Dalam Perdamaian DuniaDokumen12 halamanSoal Dinamika Peran Indonesia Dalam Perdamaian DuniaFathur Rahman FauzanBelum ada peringkat
- Media PenyimpananDokumen31 halamanMedia PenyimpananarifinznBelum ada peringkat
- Organisasi Berkas Indeks SequentialDokumen14 halamanOrganisasi Berkas Indeks SequentialFathur Rahman FauzanBelum ada peringkat
- Manajemen ProsesDokumen17 halamanManajemen ProsesdendaBelum ada peringkat
- Tugas VB - Listview PDFDokumen3 halamanTugas VB - Listview PDFFathur Rahman FauzanBelum ada peringkat
- Media PenyimpananDokumen31 halamanMedia PenyimpananarifinznBelum ada peringkat
- Penjadwalan Proses PDFDokumen26 halamanPenjadwalan Proses PDFFathur Rahman FauzanBelum ada peringkat
- SILABUS BAHASA INDONESIA - Doc Reguler PDFDokumen9 halamanSILABUS BAHASA INDONESIA - Doc Reguler PDFFathur Rahman FauzanBelum ada peringkat
- SILABUS BAHASA INDONESIA - Doc Reguler PDFDokumen9 halamanSILABUS BAHASA INDONESIA - Doc Reguler PDFFathur Rahman FauzanBelum ada peringkat
- Penjadwalan Proses PDFDokumen26 halamanPenjadwalan Proses PDFFathur Rahman FauzanBelum ada peringkat
- Handout Struktur Data PDFDokumen65 halamanHandout Struktur Data PDFFathur Rahman FauzanBelum ada peringkat
- Handout Struktur Data PDFDokumen65 halamanHandout Struktur Data PDFFathur Rahman FauzanBelum ada peringkat
- #6 Sinkronisasi PDFDokumen50 halaman#6 Sinkronisasi PDFFathur Rahman FauzanBelum ada peringkat
- Makalah Bahasa Indonesia Pelaksanaan Penilaian Prestasi Kerja Untuk Menentukan KinerjaDokumen15 halamanMakalah Bahasa Indonesia Pelaksanaan Penilaian Prestasi Kerja Untuk Menentukan KinerjaFathur Rahman FauzanBelum ada peringkat
- #6 Sinkronisasi PDFDokumen50 halaman#6 Sinkronisasi PDFFathur Rahman FauzanBelum ada peringkat