Anda mungkin juga menyukai
- Soal UtsDokumen2 halamanSoal Utsdanan darmawanBelum ada peringkat
- Modul Matematika Ekonomi 2 ATA 20202021Dokumen134 halamanModul Matematika Ekonomi 2 ATA 20202021Kartika Dwi cahyatiBelum ada peringkat
- Lisrel Edisi RevisiDokumen34 halamanLisrel Edisi RevisiMagister Sains Psikologi100% (1)
- Modul Pelatihan Lisrel CetakDokumen48 halamanModul Pelatihan Lisrel CetakRonald Girsang100% (1)
- SEM Dan LISREL (Seri LISREL Bag.1) Pengertian Teknologi Informasi, Teknologi Komunikasi, Informasi Tentang KomunikasiDokumen35 halamanSEM Dan LISREL (Seri LISREL Bag.1) Pengertian Teknologi Informasi, Teknologi Komunikasi, Informasi Tentang KomunikasiCynton100% (1)
- Statistika Tutorial Smart Pls & Lisrel FixDokumen42 halamanStatistika Tutorial Smart Pls & Lisrel Fixfidya100% (1)
- Modul SEM LisrelDokumen25 halamanModul SEM LisrelMariza MustikaDewiBelum ada peringkat
- Lisrel SEMDokumen40 halamanLisrel SEMSF KhairunnisaBelum ada peringkat
- Proposal 3B 1HDokumen40 halamanProposal 3B 1Hramadhan syahrul100% (1)
- Tutorial Analisis SEM Menggunakan Program LISREL, AMOS SPSS Dan SmartPLSDokumen23 halamanTutorial Analisis SEM Menggunakan Program LISREL, AMOS SPSS Dan SmartPLSAdi Wijaya100% (12)
- Modul-PLS DGDGDokumen29 halamanModul-PLS DGDGNurul Haqiqi100% (2)
- EkonometrikaDokumen14 halamanEkonometrikadeovanchBelum ada peringkat
- Pengantar LisrelDokumen43 halamanPengantar Lisreltheresia anggitaBelum ada peringkat
- Teori LokasiDokumen14 halamanTeori LokasiFurQan Planologi100% (3)
- Rps Ekonometrika IIDokumen9 halamanRps Ekonometrika IIAnastasya Revita SyaraniBelum ada peringkat
- Panduan LISREL Untuk BOOTSTRAPPINGDokumen5 halamanPanduan LISREL Untuk BOOTSTRAPPINGpuji santosoBelum ada peringkat
- Nilai Dari CPFRDokumen5 halamanNilai Dari CPFRAndre BhaskoroBelum ada peringkat
- Bank Soal UAS-ek Mikro Utk Bisnis S2-20171 - Feb.2018Dokumen3 halamanBank Soal UAS-ek Mikro Utk Bisnis S2-20171 - Feb.2018Gusmin Syarif AmaneBelum ada peringkat
- Analisis Deret WaktuDokumen9 halamanAnalisis Deret WaktuKiky RahayuBelum ada peringkat
- 20110204025737tugas AkhirDokumen106 halaman20110204025737tugas Akhir4d1put124100% (1)
- Anggaran PenjualanDokumen17 halamanAnggaran PenjualanNilam AmartaBelum ada peringkat
- RPS Ekonomi Regional Ganjil 2019-2020Dokumen10 halamanRPS Ekonomi Regional Ganjil 2019-2020nazipawatiBelum ada peringkat
- Full Book Eko Nomi Intern AsionalDokumen236 halamanFull Book Eko Nomi Intern AsionalWedusss GilihBelum ada peringkat
- Kel 5 Portofolio, Capm, AptDokumen30 halamanKel 5 Portofolio, Capm, AptAkuntansi PagiBelum ada peringkat
- BAB 9-Aliansi StratejikDokumen20 halamanBAB 9-Aliansi StratejikWahyu WildanBelum ada peringkat
- Bab 7 Teori KeagenanDokumen7 halamanBab 7 Teori Keagenandevi damayantiBelum ada peringkat
- Ekonometrika Panel DataDokumen1 halamanEkonometrika Panel DataFebrian IsharyadiBelum ada peringkat
- Strategi Investasi MomentumDokumen31 halamanStrategi Investasi MomentumROWLAND PASARIBUBelum ada peringkat
- Buku Ajar EkonometrikaDokumen99 halamanBuku Ajar EkonometrikaGustriLusianti100% (3)
- Kurikulum Ekonomi Syari'ah Stai SasDokumen46 halamanKurikulum Ekonomi Syari'ah Stai SasStai UnsapBelum ada peringkat
- Proposal Ekonometrika IbnuDokumen11 halamanProposal Ekonometrika IbnuBarep Adji WidhiBelum ada peringkat
- Ekonomi Manajerial Materi 16 - Analisis Karakteristik Pasar Persaingan OligopoliDokumen15 halamanEkonomi Manajerial Materi 16 - Analisis Karakteristik Pasar Persaingan OligopoliZultan Sastra AlamBelum ada peringkat
- Modul Stata - Tahapan Dan Perintah (Syntax) Mengolah Data Panel (2011)Dokumen6 halamanModul Stata - Tahapan Dan Perintah (Syntax) Mengolah Data Panel (2011)Akbar Suwardi75% (4)
- Ekonomi Manajerial 1Dokumen21 halamanEkonomi Manajerial 1Septi YanaBelum ada peringkat
- Analisa Data Berkala (Time - Series)Dokumen37 halamanAnalisa Data Berkala (Time - Series)Pramudya Arwana HermawanBelum ada peringkat
- Silabus Operation ResearchDokumen5 halamanSilabus Operation ResearchSaruna Audia YusrizalBelum ada peringkat
- Analisa Proses Bisnis Telkom SBYDokumen77 halamanAnalisa Proses Bisnis Telkom SBYhalloiirBelum ada peringkat
- Bahan Perkuliahan Studi Kelayakan BisnisDokumen55 halamanBahan Perkuliahan Studi Kelayakan BisnisRizki Firdausi Rachmadania100% (1)
- Analisis SCP Industri SusuDokumen119 halamanAnalisis SCP Industri Susularasmutia100% (1)
- Bab2 Teori Ekonomi Mikro - Pola Kegiatan EkonomiDokumen24 halamanBab2 Teori Ekonomi Mikro - Pola Kegiatan EkonomiRika Rahayu100% (1)
- Sem Dan LisrelDokumen50 halamanSem Dan LisrelUmi Ghozi-gazaBelum ada peringkat
- Makalah Pemodelan DataDokumen11 halamanMakalah Pemodelan DataAnnisah AnnisahBelum ada peringkat
- Bab III Bagian 3.1 - 3.6Dokumen16 halamanBab III Bagian 3.1 - 3.6Ayi AbdurachimBelum ada peringkat
- Contoh Laporan Praktikum Modul TransportasiDokumen18 halamanContoh Laporan Praktikum Modul Transportasikayadermawan_7407809Belum ada peringkat
- Tutorial Rapidminer 2Dokumen51 halamanTutorial Rapidminer 2Ellda Artha AirlanggaBelum ada peringkat
- Tutorial Rapidminer - 6Dokumen22 halamanTutorial Rapidminer - 6REG.A/0219101329/RIVALDI RAHMADIANBelum ada peringkat
- Modul-1 Komstat Praktikum d3Dokumen146 halamanModul-1 Komstat Praktikum d3NADZARATUL MAWADDAHBelum ada peringkat
- Gasal2324 Bab 2 Pemodelan MatematikaDokumen4 halamanGasal2324 Bab 2 Pemodelan MatematikaDimas PrasetioBelum ada peringkat
- Model SimulasiDokumen12 halamanModel Simulasi5ug1y4nt0Belum ada peringkat
- Buku Bab 11 SEM - SmartPLS4Dokumen30 halamanBuku Bab 11 SEM - SmartPLS4Thoriq AzisBelum ada peringkat
- Komputer II Modul-Manajemen-Data-Excel-Amp-Spss-Pdf-Free 1 (4 Files Merged) PDFDokumen78 halamanKomputer II Modul-Manajemen-Data-Excel-Amp-Spss-Pdf-Free 1 (4 Files Merged) PDFRahmat HidayatBelum ada peringkat
- Panduan StataDokumen60 halamanPanduan StataDian HendrawanBelum ada peringkat
- Bab Iv Lisler, SPSS, Minitab Agus Jahran Tinah 20.23.886Dokumen6 halamanBab Iv Lisler, SPSS, Minitab Agus Jahran Tinah 20.23.886Safitri ViaBelum ada peringkat
- MODUL 1 PraktikumDokumen12 halamanMODUL 1 PraktikumGani AshariBelum ada peringkat
- Tugas Statistik 1-3 Mohamad Husein/tugas 2 Ngetik Hal 205-207 Mohamad HuseinDokumen3 halamanTugas Statistik 1-3 Mohamad Husein/tugas 2 Ngetik Hal 205-207 Mohamad HuseinMohamad HuseinBelum ada peringkat
- Tugas Pembelajaran ExcelDokumen15 halamanTugas Pembelajaran ExcelIrfan PrabowoBelum ada peringkat
- Modul 12Dokumen4 halamanModul 12BewBelum ada peringkat
- 01-Modul Simulasi Siste1Dokumen13 halaman01-Modul Simulasi Siste1ipink72Belum ada peringkat
- Modul Manajemen Data (Excel & SPSS)Dokumen78 halamanModul Manajemen Data (Excel & SPSS)Kimsta Aba Takims100% (1)
- Presentasi LISRELDokumen13 halamanPresentasi LISRELRisty KharismaBelum ada peringkat
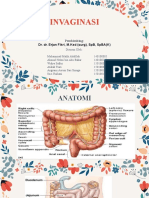
- INVAGINASIDokumen25 halamanINVAGINASIUlfa MutiaraBelum ada peringkat
- Patofisiologi AsfiksiaDokumen2 halamanPatofisiologi AsfiksiaUlfa MutiaraBelum ada peringkat
- Dosis ResepDokumen26 halamanDosis ResepUlfa MutiaraBelum ada peringkat
- BAB II Kedaruratan PsikiatriDokumen24 halamanBAB II Kedaruratan PsikiatriUlfa MutiaraBelum ada peringkat
- Leaflet Flu Etika BatukDokumen2 halamanLeaflet Flu Etika BatukUlfa MutiaraBelum ada peringkat
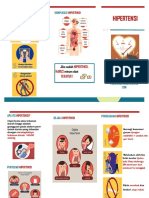
- Leaflet HipertensiDokumen2 halamanLeaflet HipertensiUlfa MutiaraBelum ada peringkat
- Leaflet HipertensiDokumen2 halamanLeaflet HipertensiUlfa MutiaraBelum ada peringkat
- Leaflet Flu Etika BatukDokumen2 halamanLeaflet Flu Etika BatukUlfa MutiaraBelum ada peringkat