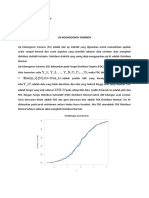
Anda mungkin juga menyukai
- Uji Normalitas Dan Homogenitas DataDokumen28 halamanUji Normalitas Dan Homogenitas DataSalman AlfarisiBelum ada peringkat
- UJI NORMALITAS PPT 1Dokumen25 halamanUJI NORMALITAS PPT 1Ahmad Fadilah TsaniBelum ada peringkat
- Uji Normalitas KolmogorovDokumen4 halamanUji Normalitas KolmogorovMulki Furqon SawiyanBelum ada peringkat
- Analisis Regresi Logistik GandaDokumen14 halamanAnalisis Regresi Logistik Gandaelang29100% (1)
- Tugas Statistika FarmasiDokumen10 halamanTugas Statistika FarmasiAstri DeaBelum ada peringkat
- Statistik Non ParametrikDokumen27 halamanStatistik Non ParametrikErin Kurnia SariBelum ada peringkat
- Modul 3 Uji Normalitas Data PDFDokumen32 halamanModul 3 Uji Normalitas Data PDFMahesa WicaksanaBelum ada peringkat
- Makalah Statistika Non ParametrikDokumen12 halamanMakalah Statistika Non Parametrikrenz_yumycake6009100% (2)
- Uji RuntunDokumen16 halamanUji RuntunRomi MymBelum ada peringkat
- Penentuan Uji Parametrik Dan Uji NonDokumen2 halamanPenentuan Uji Parametrik Dan Uji Noninha MarelBelum ada peringkat
- Tes FriedmanDokumen10 halamanTes FriedmanindryBelum ada peringkat
- Kom StatDokumen16 halamanKom StataryadiBelum ada peringkat
- Komogorlov SmirnovDokumen2 halamanKomogorlov SmirnovGelar Pandu RBelum ada peringkat
- Homogenitas Dan Normalitas DataDokumen35 halamanHomogenitas Dan Normalitas DataMTs RambatanBelum ada peringkat
- (Kelompok 4) Normalisasi Dan LinieritasDokumen48 halaman(Kelompok 4) Normalisasi Dan LinieritasAldita Adnan WrisabaBelum ada peringkat
- Uji NormalitasDokumen16 halamanUji NormalitasAnnisa FitriyaBelum ada peringkat
- Proposal Kolmogorov SmirnovDokumen4 halamanProposal Kolmogorov SmirnovRangga PradekaBelum ada peringkat
- 1) Deskripsi Materi Pertemuan 3 UJI KOLMOGOROV-SMIRNOVDokumen12 halaman1) Deskripsi Materi Pertemuan 3 UJI KOLMOGOROV-SMIRNOVTabah Heri Setiawan SudibyoBelum ada peringkat
- Analisis StatistikaDokumen8 halamanAnalisis StatistikaRahmat Budi Setiawan. KhususBelum ada peringkat
- Apk Analisis Kuantitatif FixDokumen14 halamanApk Analisis Kuantitatif Fixdwihandayani200600Belum ada peringkat
- Tugas1 - Evstat - Yasmine Safitri - 12115045Dokumen6 halamanTugas1 - Evstat - Yasmine Safitri - 12115045Yasmine SafitriBelum ada peringkat
- Uji Kolmogorov-SmirnovDokumen6 halamanUji Kolmogorov-Smirnovsudirman0103651972Belum ada peringkat
- Uji KolmogorovDokumen14 halamanUji KolmogorovMarlia Arry Yunanti,s.pdBelum ada peringkat
- Slide Pertemuan 2 Aak Uji NormalitasDokumen11 halamanSlide Pertemuan 2 Aak Uji NormalitasRinaBelum ada peringkat
- Uji Normalitas Data EditDokumen5 halamanUji Normalitas Data Editnanin uhmiazizaBelum ada peringkat
- BAB3Dokumen24 halamanBAB3Ma'mun ZahrudinBelum ada peringkat
- No 4Dokumen7 halamanNo 4Vivi DwiyaniBelum ada peringkat
- Tugas Portofolio Regresi Linear Berganda (Nila, Nurul, Hani)Dokumen21 halamanTugas Portofolio Regresi Linear Berganda (Nila, Nurul, Hani)Nila WulantikaBelum ada peringkat
- Metode Kolmogorov VIDYA DAN ARYDokumen18 halamanMetode Kolmogorov VIDYA DAN ARYMarlia Arry Yunanti,s.pdBelum ada peringkat
- Penjelasan Rumus Kolmogorov Smirnov Uji NormalitasDokumen6 halamanPenjelasan Rumus Kolmogorov Smirnov Uji Normalitasrijalul rizkiBelum ada peringkat
- Biostatistik RevisiDokumen25 halamanBiostatistik RevisiMarlia Arry YunantiBelum ada peringkat
- Uji Kenormalan DataDokumen20 halamanUji Kenormalan Datamaulana42Belum ada peringkat
- Tugas Statistik Artikel NormalitasDokumen17 halamanTugas Statistik Artikel Normalitasindra_f04Belum ada peringkat
- Kelompok 1Dokumen23 halamanKelompok 1Ulan PurnamaBelum ada peringkat
- UJI NORMALITAS Dengan SPSSDokumen7 halamanUJI NORMALITAS Dengan SPSSHendryadiBelum ada peringkat
- Metode Penelitian Kuantitatif Dilengkapi Perhitungan Manual & SPSS - Sofyan Siregar (2014)Dokumen33 halamanMetode Penelitian Kuantitatif Dilengkapi Perhitungan Manual & SPSS - Sofyan Siregar (2014)Revan Wahyu DimantaraBelum ada peringkat
- 3.uji Normalitas - Kolmogorov SmirnovDokumen12 halaman3.uji Normalitas - Kolmogorov SmirnovKoriantoBelum ada peringkat
- P13 Uji Persyaratan Analisis Data-LibreDokumen37 halamanP13 Uji Persyaratan Analisis Data-LibreresalviniBelum ada peringkat
- Pengujian Normalitas DataDokumen8 halamanPengujian Normalitas DataRemo HarsonoBelum ada peringkat
- Uji Normalitas - Pertemuan 4 PDFDokumen22 halamanUji Normalitas - Pertemuan 4 PDFZURAIDA LATIFAHBelum ada peringkat
- Laporan Uji NormalitasDokumen14 halamanLaporan Uji NormalitasDwi KurniawanBelum ada peringkat
- Uji Asumsi RegresiDokumen43 halamanUji Asumsi Regresinindyalangenluthfiani8627Belum ada peringkat
- Uji Chi-Square Dan KolmogorovDokumen9 halamanUji Chi-Square Dan KolmogorovNoval AznurBelum ada peringkat
- KELOMPOK 12 StatistikDokumen30 halamanKELOMPOK 12 StatistikFebi Ayu CahyatiBelum ada peringkat
- Statistik Inf. Kel. 3Dokumen10 halamanStatistik Inf. Kel. 3Rosi budianiBelum ada peringkat
- Uji Persyaratan Analisis Data SPSS 21 PDFDokumen9 halamanUji Persyaratan Analisis Data SPSS 21 PDFMuhamad AbdurahimBelum ada peringkat
- TUGAS KELOMPOK RangkumanDokumen5 halamanTUGAS KELOMPOK RangkumanAnisBelum ada peringkat
- Statistik 2 Kelompok B3: Metode Regresi Least Square Diagnostic TestDokumen16 halamanStatistik 2 Kelompok B3: Metode Regresi Least Square Diagnostic TestNorma Dwi HapsariBelum ada peringkat
- LN10 - Non Parametric Statistical AnalysisDokumen13 halamanLN10 - Non Parametric Statistical AnalysisGan-gan RamadhanBelum ada peringkat
- Statistik Non ParametrikDokumen12 halamanStatistik Non ParametrikChristian VieriBelum ada peringkat
- EFEKTIVITASDokumen38 halamanEFEKTIVITASPutri SetyaningtyasBelum ada peringkat
- Laporan Praktikum Ekonometrika Uji NormalitasDokumen16 halamanLaporan Praktikum Ekonometrika Uji NormalitasVennyBelum ada peringkat
- Praktikum 1 MultivariateDokumen12 halamanPraktikum 1 MultivariateMochammad NashihBelum ada peringkat
- Praktikum SPSSDokumen38 halamanPraktikum SPSSdimasBelum ada peringkat
- Langkah Lokmin Dan Uraian TugasDokumen2 halamanLangkah Lokmin Dan Uraian TugasPuji HartonoBelum ada peringkat
- Teknik Pengambilan Sampel PenelitianDokumen4 halamanTeknik Pengambilan Sampel PenelitianPuji HartonoBelum ada peringkat
- Tabel R Statistika Dan Cara MembacanyaDokumen11 halamanTabel R Statistika Dan Cara MembacanyaPuji HartonoBelum ada peringkat
- Sta Pengukuran PengetahuanDokumen2 halamanSta Pengukuran PengetahuanPuji HartonoBelum ada peringkat
- Sta Perbedaan TTG Uji StatistikDokumen1 halamanSta Perbedaan TTG Uji StatistikPuji HartonoBelum ada peringkat
- Uji NormalitasDokumen3 halamanUji NormalitasPuji HartonoBelum ada peringkat
- Uji Mann WhitneyDokumen4 halamanUji Mann WhitneyPuji HartonoBelum ada peringkat
- Uji Spearman Rank Atau RhoDokumen2 halamanUji Spearman Rank Atau RhoPuji HartonoBelum ada peringkat
- Uji NormalitasDokumen8 halamanUji NormalitasPuji HartonoBelum ada peringkat
- Uji Paired T TestDokumen8 halamanUji Paired T TestPuji HartonoBelum ada peringkat
- Uji Reliabilitas Pada SpssDokumen11 halamanUji Reliabilitas Pada SpssPuji HartonoBelum ada peringkat
- Uji Validitas Dan Reliabilitas InstrumenDokumen2 halamanUji Validitas Dan Reliabilitas InstrumenPuji HartonoBelum ada peringkat
- Uji Pearson Dan Scatter Diagram Dalam ExcelDokumen6 halamanUji Pearson Dan Scatter Diagram Dalam ExcelPuji HartonoBelum ada peringkat
- Ujii SpearmanDokumen11 halamanUjii SpearmanPuji HartonoBelum ada peringkat
- Ujii SpearmanDokumen3 halamanUjii SpearmanPuji HartonoBelum ada peringkat
- Z Tabel Mengenal Distribusi Normal Dan Cara Membaca Tabel Distribusi NormalDokumen9 halamanZ Tabel Mengenal Distribusi Normal Dan Cara Membaca Tabel Distribusi NormalPuji HartonoBelum ada peringkat
- Validitas Dan Relialibilitas InstrumenDokumen5 halamanValiditas Dan Relialibilitas InstrumenPuji HartonoBelum ada peringkat
- Z Tabel Mengenal Distribusi Normal Dan Cara Membaca Tabel Distribusi NormalDokumen9 halamanZ Tabel Mengenal Distribusi Normal Dan Cara Membaca Tabel Distribusi NormalPuji HartonoBelum ada peringkat
- Ujii SpearmanDokumen3 halamanUjii SpearmanPuji HartonoBelum ada peringkat
- Z Tabel Mengenal Distribusi Normal Dan Cara Membaca Tabel Distribusi NormalDokumen4 halamanZ Tabel Mengenal Distribusi Normal Dan Cara Membaca Tabel Distribusi NormalPuji HartonoBelum ada peringkat
- Uji Normalitas Chi SquareDokumen4 halamanUji Normalitas Chi SquareAnonymous LsTEoBoTK100% (1)
- Normalitas KolmogorovDokumen5 halamanNormalitas KolmogorovPuji HartonoBelum ada peringkat
- Pengobatan HipertensiDokumen7 halamanPengobatan HipertensiPuji HartonoBelum ada peringkat
- Independent Sample TDokumen3 halamanIndependent Sample TPuji HartonoBelum ada peringkat
- Panduan Lengkap Menguasai Statistik Dengan SPSS 17 PDFDokumen23 halamanPanduan Lengkap Menguasai Statistik Dengan SPSS 17 PDFrajasinga_45Belum ada peringkat
- Uji Hipotesis DGN SPSSDokumen38 halamanUji Hipotesis DGN SPSSHendra SuryaBelum ada peringkat
- Pengobatan HipertensiDokumen6 halamanPengobatan HipertensiPuji HartonoBelum ada peringkat
- 12 Makanan Penurun Kolesterol Tinggi Dengan Cepat Dan AmpuhDokumen2 halaman12 Makanan Penurun Kolesterol Tinggi Dengan Cepat Dan AmpuhPuji HartonoBelum ada peringkat
- Dasar Hukum Mengenai Sistem Informasi KesehatanDokumen2 halamanDasar Hukum Mengenai Sistem Informasi KesehatanPuji HartonoBelum ada peringkat