
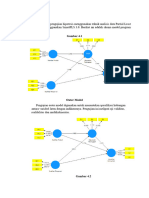
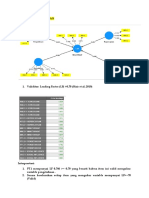
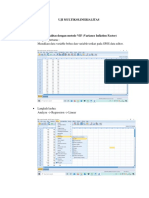
Uas Statlan
Uas Statlan
Anda mungkin juga menyukai
- Ketidakpastian Pengukuran PHDokumen6 halamanKetidakpastian Pengukuran PHKiki Teguh100% (3)
- Interpretasi SingkatDokumen10 halamanInterpretasi Singkat88 tiketBelum ada peringkat
- Bab V Hasil Survei Demografi RespondenDokumen20 halamanBab V Hasil Survei Demografi RespondenEBITBelum ada peringkat
- PembahasanDokumen4 halamanPembahasanaprilia kurnia putriBelum ada peringkat
- Tugas Besar Sistem InstrumentasiDokumen30 halamanTugas Besar Sistem InstrumentasiryanBelum ada peringkat
- Bab Iv FixDokumen20 halamanBab Iv FixNajihanBelum ada peringkat
- Model Pengukuran Atau Outer ModelDokumen9 halamanModel Pengukuran Atau Outer ModelRegina Mustika GintingBelum ada peringkat
- Perhitungan Kalibrasi Rota-Impinger - Ref. Glass Bubble Meter Flow 3 Impnger ADokumen5 halamanPerhitungan Kalibrasi Rota-Impinger - Ref. Glass Bubble Meter Flow 3 Impnger Adjainikurniyawan_47Belum ada peringkat
- Contoh Ketidakpastian FixDokumen87 halamanContoh Ketidakpastian FixRatih WindyaningrunBelum ada peringkat
- 05.4 Bab 4Dokumen23 halaman05.4 Bab 4covid19 bebasBelum ada peringkat
- Form Keskar Ahli Gizi FixxxxxxxxDokumen4 halamanForm Keskar Ahli Gizi FixxxxxxxxDara Puspa IndahBelum ada peringkat
- HitunganDokumen35 halamanHitunganInsan AmudaBelum ada peringkat
- Presentasi Laporan Akhir PLN MedanDokumen33 halamanPresentasi Laporan Akhir PLN MedanFajri HarahapBelum ada peringkat
- Perhitungan Kalibrasi Rota-Impinger - Ref. Glass Bubble Meter Flow 2 Impnger ADokumen5 halamanPerhitungan Kalibrasi Rota-Impinger - Ref. Glass Bubble Meter Flow 2 Impnger Adjainikurniyawan_47Belum ada peringkat
- File - 14-BAB-IV JDSLKDokumen12 halamanFile - 14-BAB-IV JDSLKnendraBelum ada peringkat
- Rekap Kuesioner Kompetensi PuskesmasDokumen4 halamanRekap Kuesioner Kompetensi PuskesmasPkm CiwaruBelum ada peringkat
- Time Schedule Gabungan CCODokumen1 halamanTime Schedule Gabungan CCODonzBelum ada peringkat
- Tugas Uji Asumsi KlasikDokumen5 halamanTugas Uji Asumsi KlasikjohanBelum ada peringkat
- B. Skema Program PLSDokumen6 halamanB. Skema Program PLSVandio StudioBelum ada peringkat
- 05.4 Bab 4Dokumen13 halaman05.4 Bab 4nadaBelum ada peringkat
- Realisasi 6 BulanDokumen30 halamanRealisasi 6 Bulanrudi permadiBelum ada peringkat
- Rekonsiliasi FiskalDokumen22 halamanRekonsiliasi FiskalNur Azlia HasanaBelum ada peringkat
- SMAKIN METROLOGI - 11012021-SKPElva MariyanaDokumen9 halamanSMAKIN METROLOGI - 11012021-SKPElva MariyanaElva MariyanaBelum ada peringkat
- Kurva Kalibrasi Sampel O3Dokumen1 halamanKurva Kalibrasi Sampel O3Nadia KhoirunnisaBelum ada peringkat
- Kpi GP 2019-2020Dokumen100 halamanKpi GP 2019-2020Himawan TryatmajaBelum ada peringkat
- Bab 4 Contoh Analisis Regresi BergandaDokumen17 halamanBab 4 Contoh Analisis Regresi Bergandafenilia15Belum ada peringkat
- KalibrasiDokumen4 halamanKalibrasiHapep PutihpBelum ada peringkat
- Form Hasil Evaluasi Penilaian PTT Blud 2022Dokumen2 halamanForm Hasil Evaluasi Penilaian PTT Blud 2022Wandi SiswandiBelum ada peringkat
- Accaptance SamplingDokumen27 halamanAccaptance SamplingAditya LaksonoBelum ada peringkat
- Book 1Dokumen1 halamanBook 1Fuad SolichinBelum ada peringkat
- Bab 4 PDFDokumen26 halamanBab 4 PDFFerdinand TambunanBelum ada peringkat
- Uji InstrumenDokumen9 halamanUji InstrumenIndira Laksita mlatiBelum ada peringkat
- SEM-Kepuasaan Pengguna Transportasi UmumDokumen10 halamanSEM-Kepuasaan Pengguna Transportasi UmumOky PratamaBelum ada peringkat
- Yuda - Bab IvDokumen19 halamanYuda - Bab IvAfif Fahmi MBelum ada peringkat
- 16D10242 - 2020 - 2 - 16.D1.0242 - Abi Rijkon Miftahudi - BAB IVDokumen12 halaman16D10242 - 2020 - 2 - 16.D1.0242 - Abi Rijkon Miftahudi - BAB IVRizky Ramadhan Putra RBelum ada peringkat
- Contoh Interpretasi Data SmartPLSDokumen7 halamanContoh Interpretasi Data SmartPLSFauzi NSBelum ada peringkat
- Hasil Olah Data Dan InterprestasiDokumen7 halamanHasil Olah Data Dan Interprestasigio alprinaldiBelum ada peringkat
- USP Water Criteria - En.idDokumen2 halamanUSP Water Criteria - En.idputri fatimahBelum ada peringkat
- Materi 6 - Normality Dan AutocorrelationDokumen28 halamanMateri 6 - Normality Dan AutocorrelationRevy Diaz FadhilahBelum ada peringkat
- Time Series - ARIMADokumen18 halamanTime Series - ARIMAarifBelum ada peringkat
- Pembahasan SPSS Regresi LogistikDokumen11 halamanPembahasan SPSS Regresi LogistikFebrina Sintari100% (1)
- Interprestasi Data Smart PlsDokumen14 halamanInterprestasi Data Smart PlsRizkyRamadhanBelum ada peringkat
- 1 Bab 1 Pendahuluan & PengantarDokumen7 halaman1 Bab 1 Pendahuluan & PengantarSonny Bangkit WijayaBelum ada peringkat
- Tugas 3 Mcda An Robby SepriadiDokumen8 halamanTugas 3 Mcda An Robby SepriadiJon Silas HuangBelum ada peringkat
- Chapter 17 AUDIT 2Dokumen11 halamanChapter 17 AUDIT 2novita sariBelum ada peringkat
- Innovation Spirit DT PBAL CRVC AprilDokumen101 halamanInnovation Spirit DT PBAL CRVC AprilPrasetyo WijayantoBelum ada peringkat
- Kuliah Korelasi KanonikalDokumen24 halamanKuliah Korelasi KanonikalYudiBelum ada peringkat
- Form Penilaian QC Pos DebitDokumen74 halamanForm Penilaian QC Pos DebitAhmad aji Setia prajaBelum ada peringkat
- Abk Bidan Ahli Madya PuskesmasDokumen4 halamanAbk Bidan Ahli Madya Puskesmasm.idris ansariBelum ada peringkat
- Indeks - Kepuasan - Masyarakat 2021Dokumen10 halamanIndeks - Kepuasan - Masyarakat 2021bismillah masyaallahBelum ada peringkat
- Tugas 5 - 485713 - Yoga KusumaDokumen7 halamanTugas 5 - 485713 - Yoga Kusumayoga kusumaBelum ada peringkat
- Limit Deteksi MetodeDokumen15 halamanLimit Deteksi MetodeRyan TitoBelum ada peringkat
- Hasil Uji Reliabilitas Kuesioner Persepsi Perawat Tentang Beban KerjaDokumen1 halamanHasil Uji Reliabilitas Kuesioner Persepsi Perawat Tentang Beban KerjaJuliusAdiNugrahaBelum ada peringkat
- SKM WasdalDokumen5 halamanSKM WasdalAmel ChaemBelum ada peringkat
- Perhitungan KalibrasiDokumen9 halamanPerhitungan KalibrasiMike SophieBelum ada peringkat
- Parameter Validasi Metode (Linieritas)Dokumen7 halamanParameter Validasi Metode (Linieritas)Hasrawati BaharBelum ada peringkat
- Pertemuan 6 Uji Asumsi KlasikDokumen5 halamanPertemuan 6 Uji Asumsi KlasikRizki Maulana RachmadiBelum ada peringkat
- Analisa Jurnal InternasionalDokumen7 halamanAnalisa Jurnal InternasionalAlen HabibillahBelum ada peringkat
- Uji MultikolinerialitasDokumen10 halamanUji MultikolinerialitasBaiq AlfalihunBelum ada peringkat
























































Anda mungkin juga menyukai
- Ketidakpastian Pengukuran PHDokumen6 halamanKetidakpastian Pengukuran PHKiki Teguh100% (3)
- Interpretasi SingkatDokumen10 halamanInterpretasi Singkat88 tiketBelum ada peringkat
- Bab V Hasil Survei Demografi RespondenDokumen20 halamanBab V Hasil Survei Demografi RespondenEBITBelum ada peringkat
- PembahasanDokumen4 halamanPembahasanaprilia kurnia putriBelum ada peringkat
- Tugas Besar Sistem InstrumentasiDokumen30 halamanTugas Besar Sistem InstrumentasiryanBelum ada peringkat
- Bab Iv FixDokumen20 halamanBab Iv FixNajihanBelum ada peringkat
- Model Pengukuran Atau Outer ModelDokumen9 halamanModel Pengukuran Atau Outer ModelRegina Mustika GintingBelum ada peringkat
- Perhitungan Kalibrasi Rota-Impinger - Ref. Glass Bubble Meter Flow 3 Impnger ADokumen5 halamanPerhitungan Kalibrasi Rota-Impinger - Ref. Glass Bubble Meter Flow 3 Impnger Adjainikurniyawan_47Belum ada peringkat
- Contoh Ketidakpastian FixDokumen87 halamanContoh Ketidakpastian FixRatih WindyaningrunBelum ada peringkat
- 05.4 Bab 4Dokumen23 halaman05.4 Bab 4covid19 bebasBelum ada peringkat
- Form Keskar Ahli Gizi FixxxxxxxxDokumen4 halamanForm Keskar Ahli Gizi FixxxxxxxxDara Puspa IndahBelum ada peringkat
- HitunganDokumen35 halamanHitunganInsan AmudaBelum ada peringkat
- Presentasi Laporan Akhir PLN MedanDokumen33 halamanPresentasi Laporan Akhir PLN MedanFajri HarahapBelum ada peringkat
- Perhitungan Kalibrasi Rota-Impinger - Ref. Glass Bubble Meter Flow 2 Impnger ADokumen5 halamanPerhitungan Kalibrasi Rota-Impinger - Ref. Glass Bubble Meter Flow 2 Impnger Adjainikurniyawan_47Belum ada peringkat
- File - 14-BAB-IV JDSLKDokumen12 halamanFile - 14-BAB-IV JDSLKnendraBelum ada peringkat
- Rekap Kuesioner Kompetensi PuskesmasDokumen4 halamanRekap Kuesioner Kompetensi PuskesmasPkm CiwaruBelum ada peringkat
- Time Schedule Gabungan CCODokumen1 halamanTime Schedule Gabungan CCODonzBelum ada peringkat
- Tugas Uji Asumsi KlasikDokumen5 halamanTugas Uji Asumsi KlasikjohanBelum ada peringkat
- B. Skema Program PLSDokumen6 halamanB. Skema Program PLSVandio StudioBelum ada peringkat
- 05.4 Bab 4Dokumen13 halaman05.4 Bab 4nadaBelum ada peringkat
- Realisasi 6 BulanDokumen30 halamanRealisasi 6 Bulanrudi permadiBelum ada peringkat
- Rekonsiliasi FiskalDokumen22 halamanRekonsiliasi FiskalNur Azlia HasanaBelum ada peringkat
- SMAKIN METROLOGI - 11012021-SKPElva MariyanaDokumen9 halamanSMAKIN METROLOGI - 11012021-SKPElva MariyanaElva MariyanaBelum ada peringkat
- Kurva Kalibrasi Sampel O3Dokumen1 halamanKurva Kalibrasi Sampel O3Nadia KhoirunnisaBelum ada peringkat
- Kpi GP 2019-2020Dokumen100 halamanKpi GP 2019-2020Himawan TryatmajaBelum ada peringkat
- Bab 4 Contoh Analisis Regresi BergandaDokumen17 halamanBab 4 Contoh Analisis Regresi Bergandafenilia15Belum ada peringkat
- KalibrasiDokumen4 halamanKalibrasiHapep PutihpBelum ada peringkat
- Form Hasil Evaluasi Penilaian PTT Blud 2022Dokumen2 halamanForm Hasil Evaluasi Penilaian PTT Blud 2022Wandi SiswandiBelum ada peringkat
- Accaptance SamplingDokumen27 halamanAccaptance SamplingAditya LaksonoBelum ada peringkat
- Book 1Dokumen1 halamanBook 1Fuad SolichinBelum ada peringkat
- Bab 4 PDFDokumen26 halamanBab 4 PDFFerdinand TambunanBelum ada peringkat
- Uji InstrumenDokumen9 halamanUji InstrumenIndira Laksita mlatiBelum ada peringkat
- SEM-Kepuasaan Pengguna Transportasi UmumDokumen10 halamanSEM-Kepuasaan Pengguna Transportasi UmumOky PratamaBelum ada peringkat
- Yuda - Bab IvDokumen19 halamanYuda - Bab IvAfif Fahmi MBelum ada peringkat
- 16D10242 - 2020 - 2 - 16.D1.0242 - Abi Rijkon Miftahudi - BAB IVDokumen12 halaman16D10242 - 2020 - 2 - 16.D1.0242 - Abi Rijkon Miftahudi - BAB IVRizky Ramadhan Putra RBelum ada peringkat
- Contoh Interpretasi Data SmartPLSDokumen7 halamanContoh Interpretasi Data SmartPLSFauzi NSBelum ada peringkat
- Hasil Olah Data Dan InterprestasiDokumen7 halamanHasil Olah Data Dan Interprestasigio alprinaldiBelum ada peringkat
- USP Water Criteria - En.idDokumen2 halamanUSP Water Criteria - En.idputri fatimahBelum ada peringkat
- Materi 6 - Normality Dan AutocorrelationDokumen28 halamanMateri 6 - Normality Dan AutocorrelationRevy Diaz FadhilahBelum ada peringkat
- Time Series - ARIMADokumen18 halamanTime Series - ARIMAarifBelum ada peringkat
- Pembahasan SPSS Regresi LogistikDokumen11 halamanPembahasan SPSS Regresi LogistikFebrina Sintari100% (1)
- Interprestasi Data Smart PlsDokumen14 halamanInterprestasi Data Smart PlsRizkyRamadhanBelum ada peringkat
- 1 Bab 1 Pendahuluan & PengantarDokumen7 halaman1 Bab 1 Pendahuluan & PengantarSonny Bangkit WijayaBelum ada peringkat
- Tugas 3 Mcda An Robby SepriadiDokumen8 halamanTugas 3 Mcda An Robby SepriadiJon Silas HuangBelum ada peringkat
- Chapter 17 AUDIT 2Dokumen11 halamanChapter 17 AUDIT 2novita sariBelum ada peringkat
- Innovation Spirit DT PBAL CRVC AprilDokumen101 halamanInnovation Spirit DT PBAL CRVC AprilPrasetyo WijayantoBelum ada peringkat
- Kuliah Korelasi KanonikalDokumen24 halamanKuliah Korelasi KanonikalYudiBelum ada peringkat
- Form Penilaian QC Pos DebitDokumen74 halamanForm Penilaian QC Pos DebitAhmad aji Setia prajaBelum ada peringkat
- Abk Bidan Ahli Madya PuskesmasDokumen4 halamanAbk Bidan Ahli Madya Puskesmasm.idris ansariBelum ada peringkat
- Indeks - Kepuasan - Masyarakat 2021Dokumen10 halamanIndeks - Kepuasan - Masyarakat 2021bismillah masyaallahBelum ada peringkat
- Tugas 5 - 485713 - Yoga KusumaDokumen7 halamanTugas 5 - 485713 - Yoga Kusumayoga kusumaBelum ada peringkat
- Limit Deteksi MetodeDokumen15 halamanLimit Deteksi MetodeRyan TitoBelum ada peringkat
- Hasil Uji Reliabilitas Kuesioner Persepsi Perawat Tentang Beban KerjaDokumen1 halamanHasil Uji Reliabilitas Kuesioner Persepsi Perawat Tentang Beban KerjaJuliusAdiNugrahaBelum ada peringkat
- SKM WasdalDokumen5 halamanSKM WasdalAmel ChaemBelum ada peringkat
- Perhitungan KalibrasiDokumen9 halamanPerhitungan KalibrasiMike SophieBelum ada peringkat
- Parameter Validasi Metode (Linieritas)Dokumen7 halamanParameter Validasi Metode (Linieritas)Hasrawati BaharBelum ada peringkat
- Pertemuan 6 Uji Asumsi KlasikDokumen5 halamanPertemuan 6 Uji Asumsi KlasikRizki Maulana RachmadiBelum ada peringkat
- Analisa Jurnal InternasionalDokumen7 halamanAnalisa Jurnal InternasionalAlen HabibillahBelum ada peringkat
- Uji MultikolinerialitasDokumen10 halamanUji MultikolinerialitasBaiq AlfalihunBelum ada peringkat