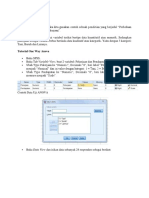
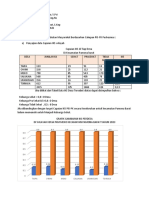
Anda mungkin juga menyukai
- Uas BiostatistikDokumen5 halamanUas BiostatistikYeti SukeniBelum ada peringkat
- Pengertian Dan Contoh Kasus Regresi Sederhana Dan BergandaDokumen57 halamanPengertian Dan Contoh Kasus Regresi Sederhana Dan BergandaRiyanthy Sasgia0109Belum ada peringkat
- Sub Mutu Jan-Jun 18Dokumen26 halamanSub Mutu Jan-Jun 18Aziz AndriyantoBelum ada peringkat
- Tugas Metodologi Penelitian - Firda Sintia - 190402029 - Vi BDokumen10 halamanTugas Metodologi Penelitian - Firda Sintia - 190402029 - Vi BFirda SintiaBelum ada peringkat
- Laporan Praktikum Biometri #2Dokumen5 halamanLaporan Praktikum Biometri #2umilsdBelum ada peringkat
- Tugas Metodologi Penelitian - Firda Sintia - 190402029 - Vi BDokumen19 halamanTugas Metodologi Penelitian - Firda Sintia - 190402029 - Vi BFirda SintiaBelum ada peringkat
- Presentasi Epidemiologi Covid 24 Juli 2021Dokumen20 halamanPresentasi Epidemiologi Covid 24 Juli 2021Ika Septiana EryaniBelum ada peringkat
- Antar VariabelDokumen17 halamanAntar VariabelHazzaBelum ada peringkat
- Tugas Biostatistik Kel 3Dokumen6 halamanTugas Biostatistik Kel 3sonia apriliaBelum ada peringkat
- Diskusi 7 - Muhammad Fandi - Statistika PendDokumen4 halamanDiskusi 7 - Muhammad Fandi - Statistika Pendmuhammad fandiBelum ada peringkat
- Situasi Program Penanggulangan TBC KBT IIDokumen18 halamanSituasi Program Penanggulangan TBC KBT IIMadeShuarjanaSusilaBelum ada peringkat
- Tugas 7 Mahyeddin 190150075Dokumen7 halamanTugas 7 Mahyeddin 190150075Yozzy channelBelum ada peringkat
- Iks Desa MengkangDokumen4 halamanIks Desa MengkangAyu MalahBelum ada peringkat
- Laporan Mingguan COVID-19 Per 3 Desember 2023Dokumen19 halamanLaporan Mingguan COVID-19 Per 3 Desember 2023Anonymous TestingBelum ada peringkat
- Iks Desa LolayanDokumen4 halamanIks Desa LolayanAyu MalahBelum ada peringkat
- Laporan Rekapitulasi Iks Kecamatan - Kecamatan Taliabu Barat Laut - 07-08-2021 - 002744Dokumen4 halamanLaporan Rekapitulasi Iks Kecamatan - Kecamatan Taliabu Barat Laut - 07-08-2021 - 002744Hasfi IvynBelum ada peringkat
- Angka Indeks TertimbangDokumen4 halamanAngka Indeks TertimbangAgustina YuniarBelum ada peringkat
- Rekapitulasi Iks Kel. Dan Desa Tahun 2021Dokumen52 halamanRekapitulasi Iks Kel. Dan Desa Tahun 2021nur tilawahBelum ada peringkat
- Hilda Nuzulia - Tugas Statistik PendidikanDokumen6 halamanHilda Nuzulia - Tugas Statistik Pendidikankhasan alfariziBelum ada peringkat
- Korelasi Pearson, Least Square Dan Product MomenDokumen27 halamanKorelasi Pearson, Least Square Dan Product MomenReadoneBelum ada peringkat
- Hasil SMD Puskesmas CampurdaratDokumen32 halamanHasil SMD Puskesmas CampurdaratintinovitasariBelum ada peringkat
- Surveilance Dan Skrining PenyDokumen59 halamanSurveilance Dan Skrining PenyPeny ArianiBelum ada peringkat
- Tugas BiostatistikDokumen7 halamanTugas Biostatistikkhumairotul zahrohBelum ada peringkat
- Laporan Anak Desa Purworejo 2022 1Dokumen21 halamanLaporan Anak Desa Purworejo 2022 1Ida SuaydahBelum ada peringkat
- Uji ANOVADokumen11 halamanUji ANOVALheylhye Allyhielhyie GacuchedziebaedhaeghieyiBelum ada peringkat
- Rekapitulasi IKS KELURAHAN TALUN RT RWDokumen2 halamanRekapitulasi IKS KELURAHAN TALUN RT RWkesling Kota KalerBelum ada peringkat
- Anggi Arwin Pratama - Tugas II Metoda InversiDokumen8 halamanAnggi Arwin Pratama - Tugas II Metoda InversiAli AliBelum ada peringkat
- Leptospirosis JabarDokumen27 halamanLeptospirosis JabarMoh. Riyan HermawanBelum ada peringkat
- Pws Anak & Ispa 2018Dokumen4 halamanPws Anak & Ispa 2018Chandra FerdianBelum ada peringkat
- Iks NagarawangiDokumen1 halamanIks NagarawangiInti MustikaBelum ada peringkat
- Tugas 7 SPSSDokumen9 halamanTugas 7 SPSSIsmail AkbarBelum ada peringkat
- Presentasi Laporan Bulanan Ruang Anak & Perinatologi 2022Dokumen24 halamanPresentasi Laporan Bulanan Ruang Anak & Perinatologi 2022Ummy YuniantiniBelum ada peringkat
- Naskah Tugas Mata Kuliah Ke 1 Statistik EkonomiDokumen1 halamanNaskah Tugas Mata Kuliah Ke 1 Statistik EkonomiAnggi SincBelum ada peringkat
- Tutorial Analisis Variabel Dummy IndepenDokumen7 halamanTutorial Analisis Variabel Dummy IndepenArda YoungBelum ada peringkat
- Laporan DiodaDokumen6 halamanLaporan DiodaAris AlfikriBelum ada peringkat
- Anstat - Zulfa Fitri AnnisaDokumen5 halamanAnstat - Zulfa Fitri AnnisaIhsan AfifBelum ada peringkat
- Bab 6-UKURAN PENYEBARANDokumen10 halamanBab 6-UKURAN PENYEBARANMarliyaBelum ada peringkat
- Statistik - Regresi Sederhana Dan BergandaDokumen10 halamanStatistik - Regresi Sederhana Dan BergandaAdrian HandaBelum ada peringkat
- Soal 2Dokumen6 halamanSoal 2Sri PramitaBelum ada peringkat
- Naskah ESPA4224 The 1Dokumen2 halamanNaskah ESPA4224 The 1bion erlan saputraBelum ada peringkat
- Korelasi RegresiDokumen26 halamanKorelasi RegresiSulthon Nur JamilBelum ada peringkat
- Teknik SamplingDokumen7 halamanTeknik SamplingAdeBelum ada peringkat
- Skrip Financial FlexibilityDokumen35 halamanSkrip Financial FlexibilityGeorge SvensonBelum ada peringkat
- Analisis UnivariatDokumen38 halamanAnalisis Univariatsaadilah faridBelum ada peringkat
- Tugeh Prof - RizandaDokumen5 halamanTugeh Prof - RizandaAnita PutriBelum ada peringkat
- Prof. Samsuridjal - PDPAI 2016 - Prof Samsuridjal - Penatalaksanaan HIV Co-Infeksi Hepatitis C - 26 Nov 2016Dokumen40 halamanProf. Samsuridjal - PDPAI 2016 - Prof Samsuridjal - Penatalaksanaan HIV Co-Infeksi Hepatitis C - 26 Nov 2016astri_wardaniBelum ada peringkat
- 3 Korelasi PearsonDokumen18 halaman3 Korelasi PearsonAnnisa RahmaniBelum ada peringkat
- Laporan Rekapitulasi IKS Tingkat Desa Kelurahan - KELURAHAN-DESA SINDANGSARI - 25-11-2020 - 025917Dokumen2 halamanLaporan Rekapitulasi IKS Tingkat Desa Kelurahan - KELURAHAN-DESA SINDANGSARI - 25-11-2020 - 025917Heti JuliawatiBelum ada peringkat
- Uji Paired T Test Dan Anova-14Dokumen16 halamanUji Paired T Test Dan Anova-14Laila Cs0201Belum ada peringkat
- Korelasi Dan Regresi Bivariat SederhanaDokumen28 halamanKorelasi Dan Regresi Bivariat SederhanaMade Bunga Asvini Kharisma SantyBelum ada peringkat
- PMKP GladaksariDokumen54 halamanPMKP GladaksariLatifah Hadi SurantoBelum ada peringkat
- Hubungan Peran Keluarga Sebagai Care Giver Dengan Kualitas Hidup Pada Pasien Lansia Diruangan Rawat Inap Rsud Pasar ReboDokumen5 halamanHubungan Peran Keluarga Sebagai Care Giver Dengan Kualitas Hidup Pada Pasien Lansia Diruangan Rawat Inap Rsud Pasar Reboniken larasatiBelum ada peringkat
- Iks Desa Tanoyan UtaraDokumen6 halamanIks Desa Tanoyan UtaraAyu MalahBelum ada peringkat
- Laporan Rekapitulasi IKS Tingkat Desa Kelurahan - KELURAHAN-DESA BANDUNGREJOSARI - 14-09-2023 - 035532Dokumen18 halamanLaporan Rekapitulasi IKS Tingkat Desa Kelurahan - KELURAHAN-DESA BANDUNGREJOSARI - 14-09-2023 - 035532KIA DANNISJANTIBelum ada peringkat
- Laporan Rekapitulasi Iks Kecamatan - Kecamatan Barumun Selatan - 26-01-2024 - 054958Dokumen3 halamanLaporan Rekapitulasi Iks Kecamatan - Kecamatan Barumun Selatan - 26-01-2024 - 054958azrulsulaimansiregarBelum ada peringkat
- Brancha Kepuasan Pasien Dan KeluargaDokumen1 halamanBrancha Kepuasan Pasien Dan Keluargavisit. rulBelum ada peringkat
- Kebijakan Malaria - Jayapura 281016 - Kasubdit MalariaDokumen41 halamanKebijakan Malaria - Jayapura 281016 - Kasubdit MalariaAurelia IntanBelum ada peringkat
- Penugasan Manajemen Data Kelompok IV - OkDokumen9 halamanPenugasan Manajemen Data Kelompok IV - OkI wayan SuardanoBelum ada peringkat
- Soal Keperawatan Manajemen Semester 7BDokumen24 halamanSoal Keperawatan Manajemen Semester 7BYuliBelum ada peringkat
- Fikss SAP ApendicitisDokumen13 halamanFikss SAP ApendicitisYuliBelum ada peringkat
- Laporan Pendahuluan GoutDokumen17 halamanLaporan Pendahuluan GoutYuliBelum ada peringkat
- Laporan Desiminasi Akhir Stase Manajemen Keperawatan Di Ruang Dahlia Rsu NegaraDokumen182 halamanLaporan Desiminasi Akhir Stase Manajemen Keperawatan Di Ruang Dahlia Rsu NegaraYuliBelum ada peringkat
- LP Decomp Cordis-Dikonversi Iccu Kelompok 6Dokumen19 halamanLP Decomp Cordis-Dikonversi Iccu Kelompok 6YuliBelum ada peringkat
- 7 LP Keperawatan JiwaDokumen123 halaman7 LP Keperawatan JiwaYuliBelum ada peringkat
- KAD, Trauma Abdomen Krisis TyroidDokumen58 halamanKAD, Trauma Abdomen Krisis TyroidYuliBelum ada peringkat
- KEPERAWATA GADAR Klp.6 Kls 6bDokumen62 halamanKEPERAWATA GADAR Klp.6 Kls 6bYuliBelum ada peringkat
- Trauma Tulang BlakangDokumen38 halamanTrauma Tulang BlakangYuliBelum ada peringkat
- TUGAS KELOMPOK 7 KRITIS CombustioDokumen61 halamanTUGAS KELOMPOK 7 KRITIS CombustioYuliBelum ada peringkat