Anda mungkin juga menyukai
- Tugas P12 (RPL) Nirwan Maulana Mustafa 11180444Dokumen2 halamanTugas P12 (RPL) Nirwan Maulana Mustafa 11180444NirwanBelum ada peringkat
- Bab 4Dokumen14 halamanBab 4anggrainiwindiBelum ada peringkat
- Evaluasi Test Masuk Kerja Dengan Microsoft ExcelDokumen2 halamanEvaluasi Test Masuk Kerja Dengan Microsoft ExcelMetodio Caetano Moniz100% (2)
- Kotlin DasarDokumen201 halamanKotlin Dasarnurmilayanti iiBelum ada peringkat
- Tugas Pertemuan 12 RPLDokumen3 halamanTugas Pertemuan 12 RPLReza Fahlevi16Belum ada peringkat
- Pengujian White Box Pada Aplikasi Form Logim Menggunakan Teknik Basic PathDokumen8 halamanPengujian White Box Pada Aplikasi Form Logim Menggunakan Teknik Basic PathRendy ArdiansyahBelum ada peringkat
- LAPORAN PRAKTIKUM JAVASCRIPT TINGKAT DASARtugas PDFDokumen8 halamanLAPORAN PRAKTIKUM JAVASCRIPT TINGKAT DASARtugas PDFannisa rizka auiaBelum ada peringkat
- Project Analisa Klasifikasi Pinjaman Untuk Sektor UMKMDokumen10 halamanProject Analisa Klasifikasi Pinjaman Untuk Sektor UMKMHazel Rahmaddio0% (1)
- Rollup, Cube & Grouping SetsDokumen6 halamanRollup, Cube & Grouping SetsFIkrianHaicalBelum ada peringkat
- Tutorial Penggunaan Safe Exam Browser PDFDokumen7 halamanTutorial Penggunaan Safe Exam Browser PDFnurjaman61Belum ada peringkat
- Test Plan My TelkomselDokumen2 halamanTest Plan My TelkomselRadenIhssanKillingmeinsideBelum ada peringkat
- Makalah DelphiDokumen19 halamanMakalah DelphiAfief Putranto PamungkasBelum ada peringkat
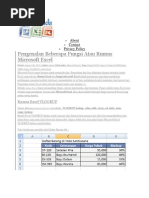
- Rumus ExcelDokumen40 halamanRumus ExcelRiefky LbdvcBelum ada peringkat
- Konteks Manajemen Proyek Dan Teknologi InformasiDokumen51 halamanKonteks Manajemen Proyek Dan Teknologi InformasiIndrha Si SqUarpantsBelum ada peringkat
- 21.melaksanakan Pengujian Unit ProgramDokumen2 halaman21.melaksanakan Pengujian Unit ProgramHalimatuSa'diah Sa'diahBelum ada peringkat
- SDLC Dan Metodologi PembangunannyaDokumen5 halamanSDLC Dan Metodologi PembangunannyanikeBelum ada peringkat
- Prinsip Dan Konsep Kualitas Perangkat LunakDokumen4 halamanPrinsip Dan Konsep Kualitas Perangkat LunakMaruli SiahaanBelum ada peringkat
- J.620100.005.02 (Mengimplementasikan User Interface)Dokumen3 halamanJ.620100.005.02 (Mengimplementasikan User Interface)Bond Cakson100% (1)
- Metode Get Dan PostDokumen10 halamanMetode Get Dan PostAan JelekBelum ada peringkat
- Soal Uas Oracle PL SQLDokumen5 halamanSoal Uas Oracle PL SQLsilvercyber19100% (1)
- Millenia RusbandiDokumen5 halamanMillenia RusbandiMillenia RusbandiBelum ada peringkat
- Kecerdasan BuatanDokumen65 halamanKecerdasan Buatanijoe_biruBelum ada peringkat
- Basis Data MysqlDokumen74 halamanBasis Data MysqlksatrioBelum ada peringkat
- Sistem Pendukung Keputusan Pengangkatan Jabatan Pada Kantor Dinas Kependudukan Dan Pencatatan Sipil Kabupaten Jayapura Menggunakan Metode AhpDokumen17 halamanSistem Pendukung Keputusan Pengangkatan Jabatan Pada Kantor Dinas Kependudukan Dan Pencatatan Sipil Kabupaten Jayapura Menggunakan Metode AhpAbbas100% (1)
- Surat Lamaran Pekerjaan PT ADVICSDokumen1 halamanSurat Lamaran Pekerjaan PT ADVICSFanlipto GusnandaBelum ada peringkat
- Belajar Java Sederhana Dengan JCreatorDokumen15 halamanBelajar Java Sederhana Dengan JCreatorEdo WinartaBelum ada peringkat
- PlotDokumen20 halamanPlotAlice Park100% (3)
- Object Oriented Programming Pada PythonDokumen5 halamanObject Oriented Programming Pada PythonSiti Rohaniyah100% (1)
- Functional Requirement InstagramDokumen3 halamanFunctional Requirement InstagramFaisal Rahman IskandDarBelum ada peringkat
- Tipe Data, Variabel, Dan ArrayDokumen22 halamanTipe Data, Variabel, Dan ArrayWulandari Nimas0% (1)
- Java CRUD Insert, Edit, Delete MySQL DatabaseDokumen9 halamanJava CRUD Insert, Edit, Delete MySQL DatabaseMedia InternetBelum ada peringkat
- Cara Membuat ERDDokumen15 halamanCara Membuat ERDMuhammad Abdu HanifanBelum ada peringkat
- Laporan Kerja PraktikDokumen33 halamanLaporan Kerja PraktikGinaya Dinda Putri100% (1)
- 11 Rumus Excel Wajib Untuk Administrasi PerkantoranDokumen7 halaman11 Rumus Excel Wajib Untuk Administrasi PerkantoranSalam AkhmadBelum ada peringkat
- Pertemuan 12Dokumen39 halamanPertemuan 12mystarletBelum ada peringkat
- ACTIVITY ATTRIBUTES TambahanDokumen4 halamanACTIVITY ATTRIBUTES Tambahanswen pattiruhuBelum ada peringkat
- Foreman Produksi Surat Lamaran KerjaDokumen9 halamanForeman Produksi Surat Lamaran KerjaK HidayahBelum ada peringkat
- Flowchart Pertemuan7Dokumen7 halamanFlowchart Pertemuan7Turboo VpnBelum ada peringkat
- Teknik KompilasiDokumen28 halamanTeknik KompilasiIrfan FaishalBelum ada peringkat
- CV - LinkedinDokumen5 halamanCV - LinkedinHRD Power Pack Industrial SolutionBelum ada peringkat
- Makalah Model View Controler: Nama: M. Rifqi Alfajri Absen: 25Dokumen6 halamanMakalah Model View Controler: Nama: M. Rifqi Alfajri Absen: 25Rifqi AlfajriBelum ada peringkat
- Rumus Fungsi Text Pada Microsoft ExcelDokumen3 halamanRumus Fungsi Text Pada Microsoft Excelsoft_cyberBelum ada peringkat
- Panduan Input SKPI BSI HDokumen3 halamanPanduan Input SKPI BSI HBryan Depati AndalasBelum ada peringkat
- FINAL Slide Pelatihan TPA Calon Karyawan PT Vale Indonesia - Duddy - 16-05-2023Dokumen119 halamanFINAL Slide Pelatihan TPA Calon Karyawan PT Vale Indonesia - Duddy - 16-05-2023muhammad nasrullahBelum ada peringkat
- Kuesioner UATDokumen4 halamanKuesioner UATandi sumardinBelum ada peringkat
- Portofolio DataDokumen15 halamanPortofolio DataZakiyyahBelum ada peringkat
- Praktikum Fungsi SQLDokumen14 halamanPraktikum Fungsi SQLnur afni syafitriBelum ada peringkat
- Switch Case OkDokumen22 halamanSwitch Case Okrony putraBelum ada peringkat
- Aplikasi Pemesanan Tiket Pesawat Berbasis Online Menggunakan PHP Dan AjaxDokumen8 halamanAplikasi Pemesanan Tiket Pesawat Berbasis Online Menggunakan PHP Dan AjaxGon FreecssBelum ada peringkat
- Silabus WEB DEVELOPER VSGADokumen9 halamanSilabus WEB DEVELOPER VSGAQod RiyaBelum ada peringkat
- Penggunaan Delimiter Di MySQLDokumen78 halamanPenggunaan Delimiter Di MySQLfanhydeBelum ada peringkat
- Makalah Perancangan Sistem Pada Sekolah TKDokumen27 halamanMakalah Perancangan Sistem Pada Sekolah TKMulti berjayaBelum ada peringkat
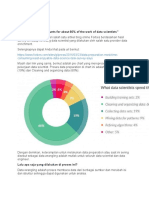
- Data Preparation in Data Science Using RDokumen13 halamanData Preparation in Data Science Using RCrimson AffandiBelum ada peringkat
- 3 Algoritma & Pemograman 3Dokumen37 halaman3 Algoritma & Pemograman 3akhmad rizali rahmaanBelum ada peringkat
- Rumus Fungsi Microsoft Excel Lengkap Contoh Dan PenjelasanDokumen11 halamanRumus Fungsi Microsoft Excel Lengkap Contoh Dan PenjelasanHiyar KkuBelum ada peringkat
- Rumus Microsoft ExelDokumen5 halamanRumus Microsoft ExelNanda Arex SambongBelum ada peringkat
- Rumus Fungsi Microsoft Excel Lengkap Contoh Dan PenjelasanDokumen6 halamanRumus Fungsi Microsoft Excel Lengkap Contoh Dan PenjelasanFahrunisaAyuKenangaAsmaraBelum ada peringkat
- Pengantar Software R - CompressedDokumen48 halamanPengantar Software R - CompressedNovita SalsabillaBelum ada peringkat
- Rumus Rumus Excel 2007 LengkapDokumen13 halamanRumus Rumus Excel 2007 LengkapAchmad Yasin100% (1)
- Contoh Fungsi ExcelDokumen6 halamanContoh Fungsi ExcelIca FajrinBelum ada peringkat
- Perka 17 Tahun 2011 Tentang Pedoman Relawan Penanggulangan BencanaDokumen46 halamanPerka 17 Tahun 2011 Tentang Pedoman Relawan Penanggulangan BencanaAlice ParkBelum ada peringkat
- 3 Kelinci Yang RakusDokumen3 halaman3 Kelinci Yang RakusAlice Park100% (1)
- Artikel IpaDokumen5 halamanArtikel IpaAlice ParkBelum ada peringkat
- Donor DarahDokumen5 halamanDonor DarahAlice ParkBelum ada peringkat
- Cover Makalah AgamaDokumen1 halamanCover Makalah AgamaAlice ParkBelum ada peringkat
- Daftar IsiDokumen2 halamanDaftar IsiAlice ParkBelum ada peringkat
- Cover Kliping PenjaskesDokumen1 halamanCover Kliping PenjaskesAlice ParkBelum ada peringkat
- Aryati Seri 2019Dokumen7 halamanAryati Seri 2019Alice ParkBelum ada peringkat
- Tabel KematianDokumen19 halamanTabel KematianAchmad McFauzanBelum ada peringkat
- Membaca File Excel Pada RStudioDokumen11 halamanMembaca File Excel Pada RStudioAlice ParkBelum ada peringkat
- Penerapan Jaringan Syaraf Tiruan Untuk Memprediksi Jumlahpeserta KBDokumen2 halamanPenerapan Jaringan Syaraf Tiruan Untuk Memprediksi Jumlahpeserta KBAlice ParkBelum ada peringkat
- Pertumbuhan PendudukDokumen14 halamanPertumbuhan PendudukAlice ParkBelum ada peringkat
- Sijabat, Meliana Novriani. 2017. Analisa Kecenderungan Jumlah Peserta Aktif KB 2012-2016Dokumen106 halamanSijabat, Meliana Novriani. 2017. Analisa Kecenderungan Jumlah Peserta Aktif KB 2012-2016Alice ParkBelum ada peringkat
- Buletin KesproDokumen44 halamanBuletin Kesprodian5christiani5malaBelum ada peringkat
- Untuk Membaca File Versi CSV Dari Dataset Kependudukan Tersebut Kita Bisa Gunakan FunctionDokumen15 halamanUntuk Membaca File Versi CSV Dari Dataset Kependudukan Tersebut Kita Bisa Gunakan FunctionAlice ParkBelum ada peringkat
- WHO CDS EPR 2007 8BahasaI PDFDokumen44 halamanWHO CDS EPR 2007 8BahasaI PDFRaHma ElfshineeBelum ada peringkat
- PlotDokumen20 halamanPlotAlice Park100% (3)
- Adriyan Instalasi Python3 Dan Ide Pada Windows10 Dqlab UPDATEDokumen56 halamanAdriyan Instalasi Python3 Dan Ide Pada Windows10 Dqlab UPDATEirfanmyj tvBelum ada peringkat
- StatistikDokumen14 halamanStatistikAlice ParkBelum ada peringkat
- Membaca File Excel Pada RStudioDokumen11 halamanMembaca File Excel Pada RStudioAlice ParkBelum ada peringkat
- Buatlah Factor Dengan TeksDokumen3 halamanBuatlah Factor Dengan TeksAlice ParkBelum ada peringkat
- Bonus Demografi 2015Dokumen6 halamanBonus Demografi 2015Alice ParkBelum ada peringkat
- WHO CDS EPR 2007 8BahasaI PDFDokumen44 halamanWHO CDS EPR 2007 8BahasaI PDFRaHma ElfshineeBelum ada peringkat
- Pertolongan PertamaDokumen27 halamanPertolongan PertamaAlice ParkBelum ada peringkat
- Pertolongan PertamaDokumen27 halamanPertolongan PertamaAlice ParkBelum ada peringkat
- Aryati Seri 2019Dokumen7 halamanAryati Seri 2019Alice ParkBelum ada peringkat
- Batasan Zat Gizi MikroDokumen3 halamanBatasan Zat Gizi MikroAlice ParkBelum ada peringkat
- Definisi PlagiarismeDokumen5 halamanDefinisi PlagiarismeAlice ParkBelum ada peringkat
- Komplikasi Kehamilan & PersalinanDokumen39 halamanKomplikasi Kehamilan & PersalinanAlice Park100% (1)