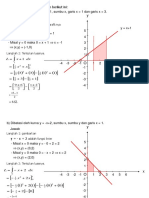
Anda mungkin juga menyukai
- Latihan Matdis2 ContohDokumen9 halamanLatihan Matdis2 Contohksoelaiman56% (9)
- Bab 5 DERET FOURIERDokumen12 halamanBab 5 DERET FOURIERfehmi ramadaniBelum ada peringkat
- STATISTIK #14 Model Regresi Logit Dan ProbitDokumen49 halamanSTATISTIK #14 Model Regresi Logit Dan ProbitDwi RiyantiBelum ada peringkat
- MATER 3 MODEL REGRESi DUA VARiABEL PERSOALAN PERKiRAAN (ESTiMASi) - OKDokumen13 halamanMATER 3 MODEL REGRESi DUA VARiABEL PERSOALAN PERKiRAAN (ESTiMASi) - OKnazipawatiBelum ada peringkat
- ITP FuzzyLogic 4Dokumen80 halamanITP FuzzyLogic 4Dede JuleoBelum ada peringkat
- Regresi Binary LogisticDokumen16 halamanRegresi Binary LogisticAl HusainiBelum ada peringkat
- Kul4 Gerbang Digital 2 2022Dokumen17 halamanKul4 Gerbang Digital 2 2022Made TuhuyulianiBelum ada peringkat
- Regresi LinierDokumen28 halamanRegresi Linierfahmi sahakaBelum ada peringkat
- MetNum7-Interpolasi BaruDokumen43 halamanMetNum7-Interpolasi BaruHikmatul Fadhilah SianiparBelum ada peringkat
- Luas Daerah (Menggambarkan) PPT 97-03Dokumen7 halamanLuas Daerah (Menggambarkan) PPT 97-03Jhon ferizalBelum ada peringkat
- Aljabar Boolean 3Dokumen27 halamanAljabar Boolean 3khusnul0% (1)
- Aldi Satria Perdana - 1900003054 - UAS Statistika ADokumen5 halamanAldi Satria Perdana - 1900003054 - UAS Statistika AWahid BisyriBelum ada peringkat
- Teknik Digital - PresentasiDokumen70 halamanTeknik Digital - PresentasiNic creativeBelum ada peringkat
- Bab IiDokumen5 halamanBab IievanBelum ada peringkat
- Regresi Linier SederhanaDokumen12 halamanRegresi Linier SederhanaVardy FahrizalBelum ada peringkat
- Aljabar BooleanDokumen12 halamanAljabar BooleanRza MaulanaBelum ada peringkat
- Limit 2Dokumen29 halamanLimit 2David ChristiantaBelum ada peringkat
- BT - Analisis Korelasi Dan Regresi - Budi Soebandriyo, SST, M. Stat - 2123Dokumen53 halamanBT - Analisis Korelasi Dan Regresi - Budi Soebandriyo, SST, M. Stat - 2123MarpinBelum ada peringkat
- Mengatasi Heteroskedasitas VariansDokumen25 halamanMengatasi Heteroskedasitas VariansAstriBelum ada peringkat
- Modul 7 Triyudi DKKDokumen23 halamanModul 7 Triyudi DKKNovianti PipinBelum ada peringkat
- Kalkulus 1Dokumen73 halamanKalkulus 1cahyaniBelum ada peringkat
- Limit Fungsi TrigonometriDokumen24 halamanLimit Fungsi TrigonometriArmizon ArmizonBelum ada peringkat
- Sebaran Normal GandaDokumen13 halamanSebaran Normal Gandasafaat yuliantoBelum ada peringkat
- JST 2Dokumen5 halamanJST 2dian techBelum ada peringkat
- Bab 2. Fungsi MatematikaDokumen28 halamanBab 2. Fungsi MatematikaGustangBelum ada peringkat
- Fungsi Non LinierDokumen38 halamanFungsi Non LinierKelas AuBelum ada peringkat
- Turunan Parsial4Dokumen27 halamanTurunan Parsial4RONALDO SITEPUBelum ada peringkat
- Bab VIII Ruang EigenDokumen45 halamanBab VIII Ruang EigenArief Rachman HakimBelum ada peringkat
- Simple Regression K-03Dokumen24 halamanSimple Regression K-03Dinnul KholisBelum ada peringkat
- Turunan Parsial4Dokumen29 halamanTurunan Parsial4D' extraordinaryBelum ada peringkat
- Ujian II FI2201 Fisika Matematik IIA - Versi TampilDokumen6 halamanUjian II FI2201 Fisika Matematik IIA - Versi TampilDelta MakmurBelum ada peringkat
- 10 RegresiDokumen26 halaman10 RegresiAdinda IdaBelum ada peringkat
- Regresi Binary LogisticDokumen10 halamanRegresi Binary Logistic502YORISSA SILVIANABelum ada peringkat
- Materi Ekonometrika I Sesi UasDokumen17 halamanMateri Ekonometrika I Sesi UasDeni58Belum ada peringkat
- 2018-2019 - Matdas Xii SMT 2 - 13 Program LinearDokumen7 halaman2018-2019 - Matdas Xii SMT 2 - 13 Program LinearSuci RahmaBelum ada peringkat
- 5 Penyederhanaan Fungsi BooleanDokumen39 halaman5 Penyederhanaan Fungsi BooleanwawanBelum ada peringkat
- Kurva Fitting KuliahDokumen33 halamanKurva Fitting KuliahTayuya Kurama MizukyBelum ada peringkat
- Week 1.2 - Linear RegressionDokumen88 halamanWeek 1.2 - Linear RegressionLa Nina Gunaswara SamuderaBelum ada peringkat
- Statdas Var Random DiskritDokumen31 halamanStatdas Var Random DiskritIpungBelum ada peringkat
- Integrasi NumerikDokumen22 halamanIntegrasi NumerikYosuaBelum ada peringkat
- Distribusi NormalDokumen34 halamanDistribusi Normalintan0% (1)
- Sistem Dinamik Muh. RifandiDokumen7 halamanSistem Dinamik Muh. RifandiMuhammad RifandiBelum ada peringkat
- Full Soal 1-12Dokumen12 halamanFull Soal 1-12Melinia FriskaBelum ada peringkat
- MatbisDokumen11 halamanMatbisIlyasa Mufti MuhyidinBelum ada peringkat
- 3b.jenis FungsiDokumen33 halaman3b.jenis FungsiNivika Tiffany SomantriBelum ada peringkat
- Materi Regresi Linear BergandaDokumen12 halamanMateri Regresi Linear BergandaLindianiBelum ada peringkat
- Regresi LogistikDokumen29 halamanRegresi LogistikMochammad Reyhan MauluddiBelum ada peringkat
- Materi Aljabar BooleanDokumen44 halamanMateri Aljabar BooleanMichael Bima Surbakti100% (1)
- Perancangan Sistem DigitalDokumen10 halamanPerancangan Sistem DigitalMukhammad MustafidBelum ada peringkat
- 10B. Logit, ProbitDokumen17 halaman10B. Logit, ProbitANDRE LIEBelum ada peringkat
- Kuliah 4. Linear Program Metode Aljabar RevisiDokumen25 halamanKuliah 4. Linear Program Metode Aljabar RevisiSalsabila AnugrahBelum ada peringkat
- 2 - Deret Taylor Dan Diferensiasi NumerikDokumen18 halaman2 - Deret Taylor Dan Diferensiasi Numerikdevi oktafiany100% (1)
- Buku ODE 1Dokumen55 halamanBuku ODE 1Kurniawati Sukma YunitaBelum ada peringkat
- Trans e DentalDokumen11 halamanTrans e DentalichannisaBelum ada peringkat
- Slide INF203 Aljabar Boolean Pertemuan 2Dokumen32 halamanSlide INF203 Aljabar Boolean Pertemuan 2Isma KaniaBelum ada peringkat
- Fix Makalah GarDokumen29 halamanFix Makalah GarRestu AdjiBelum ada peringkat
- K3 - k4 - Regresi GandaDokumen51 halamanK3 - k4 - Regresi GandaAddinlaila30 김태형Belum ada peringkat
- Distribusi Marginal BookletDokumen10 halamanDistribusi Marginal BookletJafeth DwemanserBelum ada peringkat