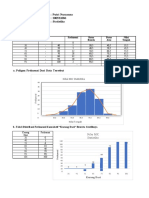
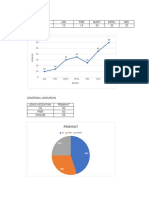
Anda mungkin juga menyukai
- Tugas 1 PEMA4210-Statistika PendidikanDokumen7 halamanTugas 1 PEMA4210-Statistika PendidikanMitra gea92% (13)
- Cara Menentukan VariabelDokumen8 halamanCara Menentukan VariabelAgusastiana AgusastianaBelum ada peringkat
- Analisis UnivariatDokumen47 halamanAnalisis UnivariatReva Susilo Tri RaharjoBelum ada peringkat
- Stat Tugas S2 1Dokumen8 halamanStat Tugas S2 1johanBelum ada peringkat
- Rini Angriani Radi - StatistikaDokumen4 halamanRini Angriani Radi - StatistikaRINI ANGRIANI RADIBelum ada peringkat
- BAB II BiostatistikDokumen5 halamanBAB II Biostatistikfebbywahyunitaa kasimBelum ada peringkat
- Diskusi 2Dokumen5 halamanDiskusi 2idcilikfrzBelum ada peringkat
- Jawaban SOAL TUTOR STATISTIKA UTSDokumen13 halamanJawaban SOAL TUTOR STATISTIKA UTSJihan LathifaBelum ada peringkat
- Statistik IDokumen26 halamanStatistik IartantoagusBelum ada peringkat
- Statistik IDokumen25 halamanStatistik ILin ChellynneBelum ada peringkat
- Diskusi 2 Statistika PendidikanDokumen4 halamanDiskusi 2 Statistika PendidikanRiski NurcahyaniBelum ada peringkat
- Christiana Ndari - 20210102259 - TO2 Statistik BisnisDokumen2 halamanChristiana Ndari - 20210102259 - TO2 Statistik Bisnis20210102259 Christiana NdariBelum ada peringkat
- Tugas 2 0616087104 02 55201 INF25512 20222 48545453Dokumen4 halamanTugas 2 0616087104 02 55201 INF25512 20222 4854545322205048 MOCH PUGA HILAL BAIHAQIEBelum ada peringkat
- 2AF - Nur Anisyah Tugas 3 StatistikDokumen2 halaman2AF - Nur Anisyah Tugas 3 StatistikNur AnisyahBelum ada peringkat
- Rapor SNBP TemplateDokumen3 halamanRapor SNBP TemplateSafira Nurul hidayahBelum ada peringkat
- Tabel Distribusi Frekuensi - Untuk MhsDokumen23 halamanTabel Distribusi Frekuensi - Untuk MhsAini Nurmalita RamadhaniBelum ada peringkat
- RNFetchBlobTmp 0c6zf6jlxizyzu7ii15w8dDokumen18 halamanRNFetchBlobTmp 0c6zf6jlxizyzu7ii15w8dTri Astuti Anuhgrah PutriBelum ada peringkat
- Tuas Statistika 3 AnjelinaDokumen6 halamanTuas Statistika 3 AnjelinaANJELINABelum ada peringkat
- Deswara Varen Ramadhani - 21108244032Dokumen7 halamanDeswara Varen Ramadhani - 21108244032Varen RamadhaniBelum ada peringkat
- Materi 5 Penyajian Data Kuantitatif Dan Stem-and-Leaf Diagram OkDokumen18 halamanMateri 5 Penyajian Data Kuantitatif Dan Stem-and-Leaf Diagram OkRian MidahBelum ada peringkat
- Tugas 1 - Statistika B - Rahmadien Fibrian Inayatullah Y.EDokumen11 halamanTugas 1 - Statistika B - Rahmadien Fibrian Inayatullah Y.EDongker 123Belum ada peringkat
- 4-Camp 2 AgregatDokumen17 halaman4-Camp 2 AgregatNgo AcaiBelum ada peringkat
- A. K3 Distribusi FrekuensiDokumen15 halamanA. K3 Distribusi FrekuensiRaid Haiqal farazsyahBelum ada peringkat
- Jawaban Lat 2Dokumen6 halamanJawaban Lat 2Indah RahmaBelum ada peringkat
- Tugas1 - Ilham MaulanaDokumen4 halamanTugas1 - Ilham MaulanaRen BaeBelum ada peringkat
- 5,6 Penyajian Data Statistik Kelas A Dan B Part 2Dokumen38 halaman5,6 Penyajian Data Statistik Kelas A Dan B Part 2ancel musBelum ada peringkat
- Tabel Pengelompokan NilaiDokumen9 halamanTabel Pengelompokan Nilaisigit s81Belum ada peringkat
- 7median Min SP Data TerkumpulDokumen14 halaman7median Min SP Data TerkumpulJiawei OngBelum ada peringkat
- Suparno 837959157 Pema4210 TMK1Dokumen3 halamanSuparno 837959157 Pema4210 TMK1Anno YukiBelum ada peringkat
- 03 Menyusun Data Ke Dalam Tabel Distribusi FrekuensiDokumen36 halaman03 Menyusun Data Ke Dalam Tabel Distribusi FrekuensiLidia PertiwiBelum ada peringkat
- Uas StatistikaDokumen2 halamanUas StatistikaPutri NurjannahBelum ada peringkat
- Komputasi Laprak Uji NormalitasDokumen9 halamanKomputasi Laprak Uji NormalitasDewi SetyawatiBelum ada peringkat
- Tugas Statistika BaruDokumen9 halamanTugas Statistika BarumahayuddinBelum ada peringkat
- Penyelesaian Diskusi 2Dokumen5 halamanPenyelesaian Diskusi 2Nita AttafarizBelum ada peringkat
- Excel Perhitungan Muhammad BakhtiyarDokumen8 halamanExcel Perhitungan Muhammad BakhtiyarSulistioBelum ada peringkat
- Mean, Median Dan ModusDokumen4 halamanMean, Median Dan ModusSandi MaulanaBelum ada peringkat
- Penyajian Statistik Dalam Bentuk Diagram Dan TabelDokumen4 halamanPenyajian Statistik Dalam Bentuk Diagram Dan TabelMeilin ZakiyaBelum ada peringkat
- Book 2Dokumen12 halamanBook 2Rose JaneBelum ada peringkat
- Modul IiiDokumen11 halamanModul IiiNavy SamuderaBelum ada peringkat
- Yasmin Rahma (Statistik 1)Dokumen6 halamanYasmin Rahma (Statistik 1)Yasmin RahmadewiBelum ada peringkat
- 2676 - Pertemuan 11 Debit RancanganDokumen26 halaman2676 - Pertemuan 11 Debit RancanganirmanovitaBelum ada peringkat
- Pertemuan 4. Penyajian DataDokumen30 halamanPertemuan 4. Penyajian DataRichrisna WaasBelum ada peringkat
- Tugas Penyajian Data TunggalDokumen3 halamanTugas Penyajian Data TunggalKania FarizkaBelum ada peringkat
- Book1 Laprak 9Dokumen3 halamanBook1 Laprak 9Ica DewiBelum ada peringkat
- Statistika Sesi 2 - TDFDokumen18 halamanStatistika Sesi 2 - TDFcristina apsariBelum ada peringkat
- Pertemuan 6Dokumen36 halamanPertemuan 6Yunia SafitriBelum ada peringkat
- Pertemuan 5Dokumen23 halamanPertemuan 5Yunia SafitriBelum ada peringkat
- Tugas TAD SUSIATI ELFITRADokumen5 halamanTugas TAD SUSIATI ELFITRAHamdan yuwapiBelum ada peringkat
- MODUL-2 - Penyajian Data - Interval KelasDokumen36 halamanMODUL-2 - Penyajian Data - Interval Kelasmohammed hikmalBelum ada peringkat
- UTS StatistikaDokumen8 halamanUTS StatistikaLilithBelum ada peringkat
- Statistika 1Dokumen10 halamanStatistika 1zounBelum ada peringkat
- Analisis SaringanDokumen10 halamanAnalisis SaringanAL HIMUBBelum ada peringkat
- STATISTIKA - Ukuran Letak Data (Kuartil, Desil, Persentil)Dokumen10 halamanSTATISTIKA - Ukuran Letak Data (Kuartil, Desil, Persentil)Nisa VebrianiBelum ada peringkat
- Distribusi FrekuensiDokumen14 halamanDistribusi FrekuensiFikas zakkyBelum ada peringkat
- Pencampuran Agregat Metode GrafisDokumen8 halamanPencampuran Agregat Metode GrafisHadiyan Putra0% (1)
- Rutherford 1Dokumen12 halamanRutherford 1rismandadesyfBelum ada peringkat
- Statistika Pendidikan Sesi 2Dokumen7 halamanStatistika Pendidikan Sesi 2Aulia YayaBelum ada peringkat
- Tugas Tabel Distribusi - Muhammad Husein SyuhadaDokumen4 halamanTugas Tabel Distribusi - Muhammad Husein SyuhadaMuhammad Husein SyuhadaBelum ada peringkat
- 02 Distribusi FrekuensiDokumen22 halaman02 Distribusi FrekuensiMuhammad HktcBelum ada peringkat
- Pembersihan Dan Sortasi BuahDokumen8 halamanPembersihan Dan Sortasi BuahBeta Sukmawati EdhitaBelum ada peringkat
- KurbanDokumen3 halamanKurbanBeta Sukmawati EdhitaBelum ada peringkat
- RPPM Fas 2022 Jan - Feb MEKARDokumen7 halamanRPPM Fas 2022 Jan - Feb MEKARBeta Sukmawati EdhitaBelum ada peringkat
- Afiefa Meiliani Edhita 1800008051 KTTRDokumen12 halamanAfiefa Meiliani Edhita 1800008051 KTTRBeta Sukmawati EdhitaBelum ada peringkat
- Berkas Nominatif TK Dan PaudDokumen20 halamanBerkas Nominatif TK Dan PaudBeta Sukmawati EdhitaBelum ada peringkat
- Format Data Profil Pendidikan NonformalDokumen2 halamanFormat Data Profil Pendidikan NonformalBeta Sukmawati EdhitaBelum ada peringkat
- Daftar Nama Siswa Bop BPKDokumen4 halamanDaftar Nama Siswa Bop BPKBeta Sukmawati EdhitaBelum ada peringkat
- Afiefa Meiliani Edhita 180008051 RPPDokumen1 halamanAfiefa Meiliani Edhita 180008051 RPPBeta Sukmawati EdhitaBelum ada peringkat
- Afiefa Meiliani Edhita - 1800008051 - B - Acara 5Dokumen25 halamanAfiefa Meiliani Edhita - 1800008051 - B - Acara 5Beta Sukmawati EdhitaBelum ada peringkat
- B 1800008051 Afiefa Meiliani EdhitaDokumen6 halamanB 1800008051 Afiefa Meiliani EdhitaBeta Sukmawati EdhitaBelum ada peringkat
- MATERI 2 Sampel Dan Populasi (Metode Sampling), Parameter Dan Statistik Statistika DeskripsiDokumen14 halamanMATERI 2 Sampel Dan Populasi (Metode Sampling), Parameter Dan Statistik Statistika DeskripsiBeta Sukmawati EdhitaBelum ada peringkat
- MATERI 2 Sampel Dan Populasi (Metode Sampling), Parameter Dan Statistik Statistika Deskripsi PDFDokumen14 halamanMATERI 2 Sampel Dan Populasi (Metode Sampling), Parameter Dan Statistik Statistika Deskripsi PDFBeta Sukmawati EdhitaBelum ada peringkat