Anda mungkin juga menyukai
- 30 Hari Jago Jualan, @DewaEkaPrayoga PDFDokumen178 halaman30 Hari Jago Jualan, @DewaEkaPrayoga PDFBahryan Purmadipta94% (33)
- Soal Dan Pembahasan Statistika InferensialDokumen18 halamanSoal Dan Pembahasan Statistika InferensialRadika Widiatmaka57% (7)
- Laporan Kunjungan BMKGDokumen28 halamanLaporan Kunjungan BMKGrobby50% (4)
- Perhitungan Uji NormalitasDokumen5 halamanPerhitungan Uji NormalitasLiliBelum ada peringkat
- Uas Kriptografi Azziz Mufqi-1Dokumen60 halamanUas Kriptografi Azziz Mufqi-1azziz mufqiBelum ada peringkat
- TPB 10Dokumen3 halamanTPB 10Fadli AshariBelum ada peringkat
- Diana Dwi Julia TSI 4Dokumen7 halamanDiana Dwi Julia TSI 4Diana Dwi JuliaBelum ada peringkat
- Indah Vera 17051059 (Analisis Korelasi Bivariat)Dokumen7 halamanIndah Vera 17051059 (Analisis Korelasi Bivariat)IndahBelum ada peringkat
- Product MomenDokumen2 halamanProduct MomenMuhamad Fahmi Al-FariziBelum ada peringkat
- Uji HomogenitasDokumen10 halamanUji HomogenitasSyamsul bahriBelum ada peringkat
- Iscka Oktovya Alan - 20610064Dokumen4 halamanIscka Oktovya Alan - 20610064F & G FajarBelum ada peringkat
- Adkb Minggu 11Dokumen8 halamanAdkb Minggu 11Dimas Dwi DarmawanBelum ada peringkat
- Tugas 5Dokumen9 halamanTugas 5Febry Giovano SidabalokBelum ada peringkat
- Paket Pembelajaran 9 Statistik DeskriptifDokumen5 halamanPaket Pembelajaran 9 Statistik DeskriptifAnita ShopBelum ada peringkat
- 257 268Dokumen10 halaman257 268annisa gispaBelum ada peringkat
- Contoh SoalDokumen4 halamanContoh SoalMUHAMMAD ARIO WINAYABelum ada peringkat
- 042 - Mazidah Qurrotu Aini - UPM STATISTIKDokumen20 halaman042 - Mazidah Qurrotu Aini - UPM STATISTIKmazidah xiuBelum ada peringkat
- Tugas Statistika Dan Probabilitas-Dikonversi-DikonversiDokumen3 halamanTugas Statistika Dan Probabilitas-Dikonversi-DikonversiFitra SunandarBelum ada peringkat
- Inka Karisma Indah - Tugas 5 Analisis Varian PbioDokumen11 halamanInka Karisma Indah - Tugas 5 Analisis Varian PbioInka KarismaBelum ada peringkat
- Tss Tugas Bu AgusDokumen4 halamanTss Tugas Bu AgusMuh AsdalBelum ada peringkat
- 9247Dokumen5 halaman9247Kerjain IdBelum ada peringkat
- Metode Regresi Polinomial Orde 2 Orde 3Dokumen11 halamanMetode Regresi Polinomial Orde 2 Orde 3Bagaskoro Dwi PrastioBelum ada peringkat
- Tugas 7 Statistik MeyDokumen5 halamanTugas 7 Statistik Meymey sriahBelum ada peringkat
- ANOVADokumen19 halamanANOVANUR AMINI TAWAKKALBelum ada peringkat
- Tugas II - WAYA TRIJAYANTI (Aplikasi Statistik Bisnis)Dokumen3 halamanTugas II - WAYA TRIJAYANTI (Aplikasi Statistik Bisnis)Muhammad RayaBelum ada peringkat
- TujuanDokumen2 halamanTujuanDesy RahayuBelum ada peringkat
- Tugas StatprobDokumen14 halamanTugas StatprobAzmi FauziaBelum ada peringkat
- Tugas Statistik Analisis Korelasi Dan RegresiDokumen11 halamanTugas Statistik Analisis Korelasi Dan RegresikhairihafizBelum ada peringkat
- Uji TukeyDokumen25 halamanUji Tukeyjdx gtBelum ada peringkat
- 5 Anakova Risma DiamiDokumen10 halaman5 Anakova Risma DiamiRisma DiamiBelum ada peringkat
- Soal2 LatihanDokumen9 halamanSoal2 Latihanshifa fauziyahBelum ada peringkat
- MetodeStatistika Sudjana Hal39321Dokumen6 halamanMetodeStatistika Sudjana Hal39321HENY SRI ASTUTIKBelum ada peringkat
- Statistik KorelasiDokumen3 halamanStatistik KorelasiFajar Nur PrastyaBelum ada peringkat
- Ringkasan Materi Pertemuan 9Dokumen7 halamanRingkasan Materi Pertemuan 9radila hanumBelum ada peringkat
- Azka - e Tugas Tutorial Ke-3 Soal 1 Revisi2Dokumen5 halamanAzka - e Tugas Tutorial Ke-3 Soal 1 Revisi2Muhammad Azka GreenUrbanomiaBelum ada peringkat
- Tugas Statistik3 - Ni Wayan Astikawati - TP2018Dokumen24 halamanTugas Statistik3 - Ni Wayan Astikawati - TP2018agus pantiBelum ada peringkat
- Laporan PerpipaanDokumen45 halamanLaporan PerpipaanAnnisaBelum ada peringkat
- Uji Normalitas Dan Uji HomogenitasDokumen13 halamanUji Normalitas Dan Uji HomogenitasBeby permata antariBelum ada peringkat
- Tgs Korelasional Astri Yuli RamadaniDokumen4 halamanTgs Korelasional Astri Yuli RamadaniAstri yuli RamadhaniBelum ada peringkat
- Tugas StatistikDokumen3 halamanTugas Statistikrati rahayuBelum ada peringkat
- Tugas Uji Homogenitas Nindi Alya SahiraDokumen3 halamanTugas Uji Homogenitas Nindi Alya SahiraAnjar Dwi Surya RamadhaniBelum ada peringkat
- Jawaban Diskusi Kelas 20 Maret 2018Dokumen4 halamanJawaban Diskusi Kelas 20 Maret 2018ari febryBelum ada peringkat
- RATNA SUMINAR Tugas Ekonomi Manajerial 2Dokumen16 halamanRATNA SUMINAR Tugas Ekonomi Manajerial 2RatnaBelum ada peringkat
- Uji Anava TunggalDokumen15 halamanUji Anava Tunggalamirul mukmininBelum ada peringkat
- Uji Regresi Dan Regresi GandaDokumen7 halamanUji Regresi Dan Regresi GandaADEL SANITBelum ada peringkat
- Tugas 6 StatistikDokumen4 halamanTugas 6 Statistiknato carvalhoBelum ada peringkat
- Tugas Uas-2023Dokumen7 halamanTugas Uas-2023Om DompetBelum ada peringkat
- Nur Aisyah - 2006103040062 - Kelas 01 - Tugas Statistika Uji Homogenitas Dan Uji TDokumen6 halamanNur Aisyah - 2006103040062 - Kelas 01 - Tugas Statistika Uji Homogenitas Dan Uji TAisyahBelum ada peringkat
- Uas Novia Dwi RamadhaniDokumen13 halamanUas Novia Dwi RamadhaniNovia Dwi RamadhaniBelum ada peringkat
- Pendahuluan Modul 5Dokumen2 halamanPendahuluan Modul 5Rory SandikaBelum ada peringkat
- Pra Kelas AnavaDokumen17 halamanPra Kelas AnavaKasmawati HudayaBelum ada peringkat
- UJI Anova 1 ArahDokumen6 halamanUJI Anova 1 Arahaulia fatmawatiBelum ada peringkat
- Statistik Yuli Kurniasih Nim 22611012112Dokumen4 halamanStatistik Yuli Kurniasih Nim 22611012112Muhammad RayaBelum ada peringkat
- HabibiDokumen3 halamanHabibiAkbar RayhanBelum ada peringkat
- Latihan Regresi Dan Korelasi 2022 With AnswerDokumen6 halamanLatihan Regresi Dan Korelasi 2022 With Answermei chee punBelum ada peringkat
- Tugas Hal 50, Nomor 2.18Dokumen2 halamanTugas Hal 50, Nomor 2.18Ni Kadek JulianiBelum ada peringkat
- Tugas Ekonometrika FixxDokumen5 halamanTugas Ekonometrika Fixxauto gamingBelum ada peringkat
- Uji Homogenitas: X Y X Y XYDokumen3 halamanUji Homogenitas: X Y X Y XYSiska Permata SariBelum ada peringkat
- Tugas Regresi BergandaDokumen7 halamanTugas Regresi BergandaMareta RestiBelum ada peringkat
- Uas BaruDokumen7 halamanUas BaruOm DompetBelum ada peringkat
- Analisis RegresiDokumen13 halamanAnalisis RegresiNeji FreitasBelum ada peringkat
- ONEDokumen2 halamanONErobbyBelum ada peringkat
- Jadwal Kegiatan MAJELIS Selama Tahun 2022Dokumen1 halamanJadwal Kegiatan MAJELIS Selama Tahun 2022robbyBelum ada peringkat
- Ekologi Lahan RawaDokumen11 halamanEkologi Lahan RawaMuhammad HusenBelum ada peringkat
- Jadwal Kegiatan MAJELIS Selama Tahun 2022Dokumen1 halamanJadwal Kegiatan MAJELIS Selama Tahun 2022robbyBelum ada peringkat
- Cover NilaDokumen2 halamanCover NilarobbyBelum ada peringkat
- Karakteristiklahanrawa PDFDokumen28 halamanKarakteristiklahanrawa PDFhendripurnamaBelum ada peringkat
- Artikel Ekologi Lahan RawaDokumen13 halamanArtikel Ekologi Lahan RawarobbyBelum ada peringkat
- V News & Edukasi Saham DiscussDokumen15 halamanV News & Edukasi Saham DiscussrobbyBelum ada peringkat
- 01 Latar Belakang SMKP-Diklat PDFDokumen56 halaman01 Latar Belakang SMKP-Diklat PDFSaiful AhmadBelum ada peringkat
- 101 - Kalam KH. ZuhdiannorDokumen27 halaman101 - Kalam KH. ZuhdiannorElva Maulida100% (9)
- 2 Dinas Kesehatan PDFDokumen204 halaman2 Dinas Kesehatan PDFrobbyBelum ada peringkat
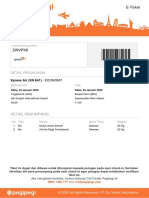
- (12ATXDE0F42) E-Ticket Pegipegi - Com 1 PDFDokumen2 halaman(12ATXDE0F42) E-Ticket Pegipegi - Com 1 PDFrobbyBelum ada peringkat
- Cara Mealkukan OffsetDokumen1 halamanCara Mealkukan OffsetrobbyBelum ada peringkat
- Lembar PengesahanDokumen1 halamanLembar PengesahanrobbyBelum ada peringkat
- Tugas AnshariDokumen7 halamanTugas AnsharirobbyBelum ada peringkat
- Kata Pengantar HidroDokumen2 halamanKata Pengantar HidrorobbyBelum ada peringkat
- Daftar IsiDokumen1 halamanDaftar IsirobbyBelum ada peringkat
- Umlah Ion HDokumen2 halamanUmlah Ion HrobbyBelum ada peringkat
- Esai FijeDokumen2 halamanEsai FijerobbyBelum ada peringkat
- Percobaan IDokumen1 halamanPercobaan IrobbyBelum ada peringkat
- Utf-8 en LAPORAN PRAKTIKUM PH Meter Larutan Penyangga PDF FreshDokumen7 halamanUtf-8 en LAPORAN PRAKTIKUM PH Meter Larutan Penyangga PDF FreshGrace OktaviaBelum ada peringkat