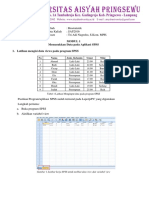
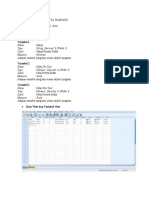
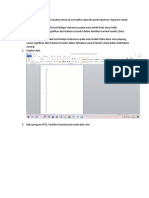
Anda mungkin juga menyukai
- Analisa Data - SopiyudinDokumen30 halamanAnalisa Data - SopiyudinRahmawati B21741920101Belum ada peringkat
- 4 adımda problem çözme: Psikoloji ve karar biliminden en iyi stratejileri kullanarak sorunları anlama ve çözmeDari Everand4 adımda problem çözme: Psikoloji ve karar biliminden en iyi stratejileri kullanarak sorunları anlama ve çözmeBelum ada peringkat
- Regresi Data Time Series Dengan SPSSDokumen54 halamanRegresi Data Time Series Dengan SPSSTiara IvandriBelum ada peringkat
- Soal Biostatistik SepDokumen5 halamanSoal Biostatistik SepYoga Pradana100% (1)
- #3 - Statistik NonparametrikDokumen38 halaman#3 - Statistik NonparametriktheresiaBelum ada peringkat
- Statistik DeskriptifDokumen15 halamanStatistik DeskriptifCeeikeyBelum ada peringkat
- Agregat Ibu HamilDokumen16 halamanAgregat Ibu HamilJalesBelum ada peringkat
- Konsep Dasar BiostatistikDokumen31 halamanKonsep Dasar BiostatistikMega DwiBelum ada peringkat
- Memasukan Data Ke SPSSDokumen3 halamanMemasukan Data Ke SPSSrosaBelum ada peringkat
- Modul Modifikasi DataDokumen17 halamanModul Modifikasi Datamohammad0% (1)
- Marge File Data Nda..Dokumen9 halamanMarge File Data Nda..Amanda NabillaBelum ada peringkat
- Normalitas Dan HomogenitasDokumen42 halamanNormalitas Dan HomogenitasNur silmiBelum ada peringkat
- Uji Mann-Whitney Dan WilcoxonDokumen31 halamanUji Mann-Whitney Dan WilcoxonNur Aini FahmiahBelum ada peringkat
- QuizDokumen7 halamanQuizUPT PUSKESMAS CILODONGBelum ada peringkat
- Uji Mann WhitneyDokumen23 halamanUji Mann WhitneyWidya AnggrainiBelum ada peringkat
- Materi Praktikum Simulasi Spss Pert. 1Dokumen44 halamanMateri Praktikum Simulasi Spss Pert. 1Hikmal KurniawanBelum ada peringkat
- Pedoman Praktikum BiostatistikDokumen45 halamanPedoman Praktikum BiostatistikDinda Resty L DBelum ada peringkat
- Makalah Statistik Bisnis - 2syahDokumen14 halamanMakalah Statistik Bisnis - 2syahSyhrl EGBelum ada peringkat
- Tugas 3 MetodepenelitiansosialDokumen7 halamanTugas 3 MetodepenelitiansosialmariarembaaciBelum ada peringkat
- Non ParametrikDokumen39 halamanNon ParametriktetsuuuuBelum ada peringkat
- BD DemsaDokumen30 halamanBD DemsaLinda Alifia YuliantiBelum ada peringkat
- Tugas 7Dokumen3 halamanTugas 7Riska AfryaniBelum ada peringkat
- MAD TampilDokumen26 halamanMAD TampilMutia JuwitaBelum ada peringkat
- Bengkel SPSS PDFDokumen94 halamanBengkel SPSS PDFeyaa0aliaBelum ada peringkat
- Metode KuantitatifDokumen4 halamanMetode KuantitatifUPT PUSKESMAS CILODONGBelum ada peringkat
- Bab 4 Analisis DeskriptifDokumen23 halamanBab 4 Analisis DeskriptifDelanaura PuspitasariBelum ada peringkat
- Uji StatistikDokumen16 halamanUji StatistikNugrahini NormalitasariBelum ada peringkat
- Kelompok 6 - Makalah Uji Linearitas RevDokumen19 halamanKelompok 6 - Makalah Uji Linearitas RevZoimatul FitriaBelum ada peringkat
- Inf0733 06PDokumen30 halamanInf0733 06PRenaldi FernandoBelum ada peringkat
- Statistika ParametrikDokumen48 halamanStatistika ParametrikNikeBelum ada peringkat
- Makalah Uji Normalitas StatistikaDokumen18 halamanMakalah Uji Normalitas StatistikaBima LintangBelum ada peringkat
- Modul Praktikum SPSS Statistika Ekonomi Inferensial - 2023Dokumen59 halamanModul Praktikum SPSS Statistika Ekonomi Inferensial - 2023mn22.cicihBelum ada peringkat
- 007 - Ni Putu Vika Suryandani (Resume Uji Hipotesis)Dokumen7 halaman007 - Ni Putu Vika Suryandani (Resume Uji Hipotesis)DayuAnanda AnandaBelum ada peringkat
- Bab 2 Metode Analitik ParametrikDokumen11 halamanBab 2 Metode Analitik ParametrikW SumaBelum ada peringkat
- Uji Persyaratan AnalisisDokumen14 halamanUji Persyaratan AnalisisMike Nurmalia SariBelum ada peringkat
- LKK 1 BLOK 18 2017 SPSSAnalisis Univariat Dan Bivariat Untuk Variabel KategorikDokumen7 halamanLKK 1 BLOK 18 2017 SPSSAnalisis Univariat Dan Bivariat Untuk Variabel KategorikSONIA VANDURI SEJABelum ada peringkat
- 7 Stat Non-Parametrik-Sign TestDokumen40 halaman7 Stat Non-Parametrik-Sign TestKima MuskimanBelum ada peringkat
- Laporan Praktikum Statistik Modul 2 Kel 38Dokumen62 halamanLaporan Praktikum Statistik Modul 2 Kel 38Haris Agung WicaksonoBelum ada peringkat
- Persiapan Pelaksanaan Kegiatan EpidemiologiDokumen29 halamanPersiapan Pelaksanaan Kegiatan EpidemiologiBreakin' Monday'Belum ada peringkat
- Pertemuan 1 Pengantar StatistikDokumen41 halamanPertemuan 1 Pengantar StatistikDAMIANUS ALEXANDER WOKANUBUNBelum ada peringkat
- Modul SPSS 20 Nov 2020Dokumen17 halamanModul SPSS 20 Nov 2020KeziaBelum ada peringkat
- Modul1 Latihan SPSSDokumen4 halamanModul1 Latihan SPSSNanda Yulis TiaBelum ada peringkat
- JAWABAN UTS GerontikDokumen6 halamanJAWABAN UTS Gerontikreka dealfiBelum ada peringkat
- Vivi Nusita Habsari - Eas Statistik 2Dokumen29 halamanVivi Nusita Habsari - Eas Statistik 2Vivi NusitaBelum ada peringkat
- MAKALAH Biplot - RevDokumen11 halamanMAKALAH Biplot - RevalyaBelum ada peringkat
- Pengenalan SPSSDokumen21 halamanPengenalan SPSSArya Cakra BuanaBelum ada peringkat
- Statistik Chi SquareDokumen29 halamanStatistik Chi SquareangghyBelum ada peringkat
- Bahan Metlid SPSS Latihan Dan Mendeley 2Dokumen29 halamanBahan Metlid SPSS Latihan Dan Mendeley 2Syadita CholifaBelum ada peringkat
- Chi SquareDokumen10 halamanChi SquareDeni Elsya Widya 2005111299Belum ada peringkat
- Analisis Univariat StatistikDokumen19 halamanAnalisis Univariat StatistiknidiaBelum ada peringkat
- Data EpidemiologiDokumen42 halamanData Epidemiologiafina firdaBelum ada peringkat
- Catatan Biostatistik 21 AgustusDokumen12 halamanCatatan Biostatistik 21 AgustusfaizahBelum ada peringkat
- Makalah KLP 6 (19 BKT 07) - Statistik PDD - CompressedDokumen16 halamanMakalah KLP 6 (19 BKT 07) - Statistik PDD - CompressedBalqis Salsabil AsyrafBelum ada peringkat
- Analsisi DataDokumen41 halamanAnalsisi DataPuskesmas KabirBelum ada peringkat
- Project Statistika Dasar Kelompok-3Dokumen13 halamanProject Statistika Dasar Kelompok-3Nova SinagaBelum ada peringkat
- SPSS 02Dokumen19 halamanSPSS 02setiono 90Belum ada peringkat
- SPSS - Hypothesis TestDokumen40 halamanSPSS - Hypothesis TestIndraBelum ada peringkat
- Materi 9 MetopenDokumen27 halamanMateri 9 Metopenanggray duvitaBelum ada peringkat
- (Rev) Kelompok 4 Uji Statistik Deskriptif Binomial & Chi KuadratDokumen43 halaman(Rev) Kelompok 4 Uji Statistik Deskriptif Binomial & Chi KuadratAinun latifah hanumBelum ada peringkat
- Turgor Kulit Bukan PenyakitDokumen1 halamanTurgor Kulit Bukan PenyakitJalesBelum ada peringkat
- SK Soft SkillDokumen4 halamanSK Soft SkillJalesBelum ada peringkat
- Asma BronchialDokumen15 halamanAsma BronchialJalesBelum ada peringkat
- Akses IntravenaDokumen9 halamanAkses IntravenaJalesBelum ada peringkat