Anda mungkin juga menyukai
- RANGE, DEVIASI, DEVIASI RATA-RATA .Kelompok 3Dokumen25 halamanRANGE, DEVIASI, DEVIASI RATA-RATA .Kelompok 3Sidik Asrofi50% (2)
- Mean, Median, ModusDokumen13 halamanMean, Median, ModusIrma Nurmayanti100% (1)
- Cara Hitung Standar DeviasiDokumen16 halamanCara Hitung Standar DeviasiCici ClardianBelum ada peringkat
- Bahan Statistik Deskriptif NumerikDokumen4 halamanBahan Statistik Deskriptif NumerikaliemBelum ada peringkat
- Tugas 1 Metode StatistikaDokumen5 halamanTugas 1 Metode StatistikaDhendy WahyuBelum ada peringkat
- Statistik Deskriptif Teknik Industri Pertemuan IIDokumen28 halamanStatistik Deskriptif Teknik Industri Pertemuan IIRisdya SantosoBelum ada peringkat
- BIOSTATISTIKADokumen36 halamanBIOSTATISTIKAlisaBelum ada peringkat
- SOAL DAN JAWABN SP LALA AGUSTINA KLMPK 6Dokumen6 halamanSOAL DAN JAWABN SP LALA AGUSTINA KLMPK 6Lala AgustinaBelum ada peringkat
- Makalah Statistik Variabilitas DataDokumen17 halamanMakalah Statistik Variabilitas DataKhairun Nisya Farenza100% (3)
- Tugas StatistikDokumen19 halamanTugas Statistikhafsah tahirBelum ada peringkat
- Statistik Dasar Untuk Data ScientistDokumen20 halamanStatistik Dasar Untuk Data ScientistFajar subeki100% (2)
- Diskusi 4 StastistikaDokumen1 halamanDiskusi 4 StastistikaimamBelum ada peringkat
- Teori Analisis DeskriptifDokumen31 halamanTeori Analisis DeskriptifYunita RatihBelum ada peringkat
- BAB VI - Akhir A5Dokumen168 halamanBAB VI - Akhir A5Robait Usman67% (3)
- Makalah Statistika 3Dokumen35 halamanMakalah Statistika 3TOMY RISWANTOBelum ada peringkat
- Analisis Deskriptif - Agung Dirgantara Namangboling, RD, M.GZ, AIFODokumen10 halamanAnalisis Deskriptif - Agung Dirgantara Namangboling, RD, M.GZ, AIFOAgung Dirgantara Namangboling, M.Gz, Dietisien, AIFOBelum ada peringkat
- Diskusi 1Dokumen3 halamanDiskusi 15S ChannelBelum ada peringkat
- Pengertian MeanDokumen3 halamanPengertian Meanclaudius lukito jarariBelum ada peringkat
- Tugas StatistikaDokumen10 halamanTugas StatistikahunianBelum ada peringkat
- Serly Statiska 3Dokumen2 halamanSerly Statiska 3Mikaelaserly SerlyBelum ada peringkat
- Makalah Ukuran DispersiDokumen14 halamanMakalah Ukuran DispersiSilvia SuyitnoBelum ada peringkat
- Powerpoint Statistik BigsonDokumen22 halamanPowerpoint Statistik BigsonPudin SyarifBelum ada peringkat
- B2B SEO Strategy by SlidesgoDokumen14 halamanB2B SEO Strategy by Slidesgomuhammadreskyramadhan75Belum ada peringkat
- DISKUSI 6 TerbaruDokumen4 halamanDISKUSI 6 TerbaruDewi PuspitasariBelum ada peringkat
- Kuis Statistik KesehatanDokumen3 halamanKuis Statistik KesehatanlatifaBelum ada peringkat
- Tugas I Statika ProbabilitasDokumen32 halamanTugas I Statika Probabilitasagasi rantealloBelum ada peringkat
- Kel 7 Permodelan EstimasiDokumen19 halamanKel 7 Permodelan EstimasiMellysa CalderaBelum ada peringkat
- Makalah Statistika 9 Dan 10Dokumen13 halamanMakalah Statistika 9 Dan 10Nur HopipahBelum ada peringkat
- Tugas Mandiri Penelitian Pendidikan Kimia: Dosen PengampuDokumen8 halamanTugas Mandiri Penelitian Pendidikan Kimia: Dosen PengampuMirandaAyuBelum ada peringkat
- Statistika DeskriptifDokumen13 halamanStatistika DeskriptifAiman AyadiBelum ada peringkat
- Tipe 3 A5 (14,8x21 CM)Dokumen14 halamanTipe 3 A5 (14,8x21 CM)Stasiun NgapakBelum ada peringkat
- KesimpulanDokumen3 halamanKesimpulanVanessa PutriBelum ada peringkat
- Kelompok 4 StatistikaDokumen16 halamanKelompok 4 StatistikaAprianto SaragihBelum ada peringkat
- Makalah Statistik Kel.4Dokumen23 halamanMakalah Statistik Kel.4Dhila AuliyahBelum ada peringkat
- Tugas DS 2 - ReviewDokumen3 halamanTugas DS 2 - ReviewDebi Rizky RamadhanaBelum ada peringkat
- Makalah Statistika Kelompok 1Dokumen15 halamanMakalah Statistika Kelompok 1WiwidBelum ada peringkat
- T1 - Statistika - Nurjannah. DS - 1921041022 - S102Dokumen11 halamanT1 - Statistika - Nurjannah. DS - 1921041022 - S102NurjannahDSBelum ada peringkat
- Pengertian StatistikaDokumen5 halamanPengertian StatistikaFachrul AlamBelum ada peringkat
- Dasar Statistika Terapan - PLP 1 - 28 Sep 2021Dokumen46 halamanDasar Statistika Terapan - PLP 1 - 28 Sep 2021Abd Della HoyaBelum ada peringkat
- Statistik DeskriptifDokumen38 halamanStatistik DeskriptifIrma Puspita50% (2)
- Pengantar Statistik Sosial Pertemuan3 Modul3 (20120923)Dokumen23 halamanPengantar Statistik Sosial Pertemuan3 Modul3 (20120923)Irene Margaret100% (1)
- Fajarika Kinasih Tugas Varians & Standar DeviasiDokumen6 halamanFajarika Kinasih Tugas Varians & Standar DeviasiFajarika KinasihBelum ada peringkat
- Isi Makalah Dian Statistik PsDokumen10 halamanIsi Makalah Dian Statistik PsAzar SetiawanBelum ada peringkat
- Metode AnalisisDokumen23 halamanMetode AnalisisRizka AnisaBelum ada peringkat
- BAB II Statistika DeskrritifDokumen15 halamanBAB II Statistika DeskrritifFateh HalmarBelum ada peringkat
- Variansi Dan Deviasi StandarDokumen4 halamanVariansi Dan Deviasi StandarSeptirianiBelum ada peringkat
- Statistika EkonomiDokumen1 halamanStatistika EkonomikrisnaachaaBelum ada peringkat
- Dari Wikipedia Bahasa IndonesiaDokumen16 halamanDari Wikipedia Bahasa IndonesiaStefani Melfiana GintoeBelum ada peringkat
- Modus Sssssssss SsssssDokumen17 halamanModus Sssssssss SsssssDkrisno SimbolonBelum ada peringkat
- Makalah Ukuran Penyebaran StatistikDokumen6 halamanMakalah Ukuran Penyebaran StatistikRifay PermanaBelum ada peringkat
- STATISTIK OLAHRAGA (Statistika Deskriptif) K-3Dokumen16 halamanSTATISTIK OLAHRAGA (Statistika Deskriptif) K-3Nita CahyaniBelum ada peringkat
- Statistik Deskriptif Dan DiferensialDokumen27 halamanStatistik Deskriptif Dan DiferensialAgus mBelum ada peringkat
- Makalah Kelompok 4Dokumen18 halamanMakalah Kelompok 4Tira GusniatiBelum ada peringkat
- Peluang Elok PDFDokumen14 halamanPeluang Elok PDFRukha Heny PramubinasihBelum ada peringkat
- MAKALAH StatistikDokumen35 halamanMAKALAH StatistikInggrit SuniBelum ada peringkat
- Makalah Kelompok 1 Penyebaran RangeDokumen11 halamanMakalah Kelompok 1 Penyebaran RangeYenni SaragihBelum ada peringkat
- Statistik DeskriptifDokumen9 halamanStatistik Deskriptifyuni arianiBelum ada peringkat
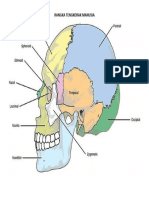
- Rangka Tengkorak ManusiaDokumen1 halamanRangka Tengkorak ManusiaaryaBelum ada peringkat
- Contoh Angket Siswa Terhadap Minat PembelajaranDokumen3 halamanContoh Angket Siswa Terhadap Minat PembelajaranaryaBelum ada peringkat
- Roap Map KehumasanDokumen3 halamanRoap Map KehumasanaryaBelum ada peringkat
- Foto Unit Produksi FixDokumen2 halamanFoto Unit Produksi FixaryaBelum ada peringkat
- Instrumen Supervisi K MerdekaDokumen15 halamanInstrumen Supervisi K MerdekaaryaBelum ada peringkat
- Jurnal - David Yavis-MergedDokumen4 halamanJurnal - David Yavis-MergedaryaBelum ada peringkat
- Surat Pertemuan Orang TuaDokumen1 halamanSurat Pertemuan Orang TuaaryaBelum ada peringkat
- 1.pedoman Pemilik CalyaDokumen286 halaman1.pedoman Pemilik CalyaaryaBelum ada peringkat
- Format Rekap Pendataan Peserta Uji Kompetensi 2023 TKRDokumen4 halamanFormat Rekap Pendataan Peserta Uji Kompetensi 2023 TKRaryaBelum ada peringkat
- Road Map Pemilihan Konsentrasi KeahlianDokumen13 halamanRoad Map Pemilihan Konsentrasi KeahlianaryaBelum ada peringkat
- 3.sistem Audio Tipe GDokumen71 halaman3.sistem Audio Tipe GaryaBelum ada peringkat
- RPP 1Dokumen15 halamanRPP 1aryaBelum ada peringkat
- Rekomendasi PBDDokumen18 halamanRekomendasi PBDaryaBelum ada peringkat
- Silabus Las Busur Manual XII GanjilDokumen9 halamanSilabus Las Busur Manual XII GanjilaryaBelum ada peringkat
- Silabus Las Mig-Mag XiiDokumen12 halamanSilabus Las Mig-Mag XiiaryaBelum ada peringkat
- RPP 2Dokumen7 halamanRPP 2aryaBelum ada peringkat
- RPP 2Dokumen15 halamanRPP 2aryaBelum ada peringkat
- RPP 4Dokumen9 halamanRPP 4aryaBelum ada peringkat
- 01 Analisis Minggu EfektifDokumen2 halaman01 Analisis Minggu EfektifaryaBelum ada peringkat
- RPP 1Dokumen6 halamanRPP 1aryaBelum ada peringkat
- RPP 3Dokumen6 halamanRPP 3aryaBelum ada peringkat
- RPP 1Dokumen15 halamanRPP 1aryaBelum ada peringkat
- MODUL AJAR PPKN SMADokumen18 halamanMODUL AJAR PPKN SMAaryaBelum ada peringkat
- Mekanisme Uas KLS XiiDokumen23 halamanMekanisme Uas KLS XiiaryaBelum ada peringkat
- 1.1 Rancangan Bahan Ajar Dasar-Dasar Teknik Perawatan GedungDokumen5 halaman1.1 Rancangan Bahan Ajar Dasar-Dasar Teknik Perawatan GedungaryaBelum ada peringkat
- RPP PPKN Kelas XIIDokumen1 halamanRPP PPKN Kelas XIIaryaBelum ada peringkat
- Laporan Kegiatan P5BKDokumen6 halamanLaporan Kegiatan P5BKaryaBelum ada peringkat
- CP PPKN - SMK - 10Dokumen3 halamanCP PPKN - SMK - 10aryaBelum ada peringkat
- Sketsa SMKN 2 DUMAIDokumen1 halamanSketsa SMKN 2 DUMAIaryaBelum ada peringkat
- Data Kota BandungDokumen8 halamanData Kota BandungaryaBelum ada peringkat