Anda mungkin juga menyukai
- Perawtan MesinDokumen7 halamanPerawtan Mesinmx AdrianBelum ada peringkat
- UTS Teknik & Analisa KehandalanDokumen5 halamanUTS Teknik & Analisa Kehandalanberkah fajarBelum ada peringkat
- Analisis Keandalan Sistem PDFDokumen12 halamanAnalisis Keandalan Sistem PDFNurul ChusnaBelum ada peringkat
- Basic Maintenance ConceptDokumen44 halamanBasic Maintenance Conceptmuhammad raviBelum ada peringkat
- UTS Teknik Dan Analisa KehandalanDokumen4 halamanUTS Teknik Dan Analisa KehandalanAbid MuflihBelum ada peringkat
- Indra P@MDokumen4 halamanIndra P@MAhmad Indra Sakti HarahapBelum ada peringkat
- Dasar RamsDokumen9 halamanDasar RamsLuqman KumaraBelum ada peringkat
- P2 Modul Praktikum Ram 2023Dokumen14 halamanP2 Modul Praktikum Ram 2023ILham FadhillBelum ada peringkat
- P1 Modul Praktikum Ram 2023Dokumen10 halamanP1 Modul Praktikum Ram 2023ILham FadhillBelum ada peringkat
- 07 Kehandalan Sistem PDFDokumen11 halaman07 Kehandalan Sistem PDFRandy Gibson Oloan SigalinggingBelum ada peringkat
- ReliabilityDokumen7 halamanReliabilityHamam AbuBelum ada peringkat
- SCE - Pertemuan Keempat - Bath Taub Curve Dan Constant Failure ModelDokumen26 halamanSCE - Pertemuan Keempat - Bath Taub Curve Dan Constant Failure Modelyoga pangestuBelum ada peringkat
- III - PMT Keandalan SystemDokumen39 halamanIII - PMT Keandalan SystemMulti RiyadiBelum ada peringkat
- Teknik KeandalanDokumen51 halamanTeknik KeandalanPacis IrwantoBelum ada peringkat
- Tegar Ardiyan Akbar - 21050118120006 - UTS - Teknik Analisa Dan KehandalanDokumen5 halamanTegar Ardiyan Akbar - 21050118120006 - UTS - Teknik Analisa Dan KehandalanAbid MuflihBelum ada peringkat
- PAPER Analisa Keandalan Sistem PDFDokumen7 halamanPAPER Analisa Keandalan Sistem PDFAkbar NafisBelum ada peringkat
- KualitasDokumen5 halamanKualitas091111Belum ada peringkat
- Analisis Hazard Rate, Metode Keandalan, MTTFDokumen18 halamanAnalisis Hazard Rate, Metode Keandalan, MTTFChio HahaBelum ada peringkat
- Penjadwalan Preventive Maintenance Di PT PDFDokumen11 halamanPenjadwalan Preventive Maintenance Di PT PDFZlatanBahrainmovicAbdullahBelum ada peringkat
- Manajemen Perawatan Alat BeratDokumen4 halamanManajemen Perawatan Alat Beratlowongan kerjaBelum ada peringkat
- Definisi KinerjaDokumen29 halamanDefinisi KinerjakurniasaputrafadlyBelum ada peringkat
- Meizy Anggun Ningsih-tt5a-Menghitung MTBF Power SupplyDokumen10 halamanMeizy Anggun Ningsih-tt5a-Menghitung MTBF Power SupplyMeizy AnggunBelum ada peringkat
- 3BAB8.Pemeliharaan Sistem Tanpa SoalDokumen23 halaman3BAB8.Pemeliharaan Sistem Tanpa SoalSofyan RBelum ada peringkat
- Solichana Yusuf-TT5A-Spesifikasi Komponen Dan Peralatan (Tugas 3)Dokumen8 halamanSolichana Yusuf-TT5A-Spesifikasi Komponen Dan Peralatan (Tugas 3)solichana yusufBelum ada peringkat
- Kelompok 4 - B - TugasKelompok1Dokumen68 halamanKelompok 4 - B - TugasKelompok1Ricky Muhammad FirdausBelum ada peringkat
- Pertemuan 5 - Konsep Keandalan RBDDokumen27 halamanPertemuan 5 - Konsep Keandalan RBDAsdf GhjklBelum ada peringkat
- M4. Failure RateDokumen19 halamanM4. Failure RateWildatus SholichahBelum ada peringkat
- Fungsi KeandalanDokumen11 halamanFungsi KeandalanMuswardi WardiBelum ada peringkat
- 5796 5422 1 PBDokumen9 halaman5796 5422 1 PBJoshwa SimamoraBelum ada peringkat
- Laporan MTBF NisaDokumen11 halamanLaporan MTBF Nisanisa karimahBelum ada peringkat
- Keandalan Dan KetersediaanDokumen18 halamanKeandalan Dan KetersediaanIdham A. Djufri100% (1)
- Analisis Keandalan Pada Boiler PLTU Dengan Metode FMEADokumen7 halamanAnalisis Keandalan Pada Boiler PLTU Dengan Metode FMEAMuhammad KamalBelum ada peringkat
- Keandalan Dan Penentuan Interval Waktu Perawatan IcaaDokumen4 halamanKeandalan Dan Penentuan Interval Waktu Perawatan IcaaArss Sakti SetyaBelum ada peringkat
- Definisi Keandalan IIDokumen16 halamanDefinisi Keandalan IIDika Rahayu WidianaBelum ada peringkat
- Aksan, S.T.,M.T. - Proteksi Arus Lebih 3 Phasa (OCR)Dokumen23 halamanAksan, S.T.,M.T. - Proteksi Arus Lebih 3 Phasa (OCR)Muhammad SalehBelum ada peringkat
- Kapita Selekta Teknik MesinDokumen5 halamanKapita Selekta Teknik MesinMaria SimbolonBelum ada peringkat
- Materi Penyusun PPT Kelompok 2Dokumen12 halamanMateri Penyusun PPT Kelompok 2RATNA SITIBelum ada peringkat
- Probability DistributionDokumen23 halamanProbability DistributionTeddy ErnantoBelum ada peringkat
- Kemangkusan Algoritma Pada Beberapa Variasi Quick SortDokumen7 halamanKemangkusan Algoritma Pada Beberapa Variasi Quick SortAlifa Nurani PutriBelum ada peringkat
- Modul 1 Lini Produksi PpicDokumen26 halamanModul 1 Lini Produksi PpicMuhammad Faisal KbaBelum ada peringkat
- ITS Undergraduate 15452 Paper 1359193Dokumen7 halamanITS Undergraduate 15452 Paper 1359193PRANOTOSUKMOBelum ada peringkat
- Tugas 1 - Meutia Zamieyus - 09011181722018Dokumen5 halamanTugas 1 - Meutia Zamieyus - 09011181722018faroukakbar15Belum ada peringkat
- Bab 1 Analisa Kinerja SistemDokumen7 halamanBab 1 Analisa Kinerja SistemFarmin VillesBelum ada peringkat
- Sistem Waktunyata 2013 BY DR. LINGGADokumen34 halamanSistem Waktunyata 2013 BY DR. LINGGAikaamaliasBelum ada peringkat
- Tugas Perawatan MesinDokumen8 halamanTugas Perawatan MesinYazid AkbarBelum ada peringkat
- LN 10 - OkDokumen17 halamanLN 10 - OkMuhk AnwarBelum ada peringkat
- Kelompok 4 - Kelas A - Tugas Sistem Pemeliharaan Reliability FunctionDokumen22 halamanKelompok 4 - Kelas A - Tugas Sistem Pemeliharaan Reliability FunctionIang IpBelum ada peringkat
- 3 - Kompleksitas Algoritma-2Dokumen9 halaman3 - Kompleksitas Algoritma-2Rian OktafianiBelum ada peringkat
- Bab Iii MaintainabilityDokumen13 halamanBab Iii MaintainabilityHilmi FauziBelum ada peringkat
- Bab II Modul 2 Epsk Modul 2Dokumen25 halamanBab II Modul 2 Epsk Modul 2Apriandi SilalahiBelum ada peringkat
- Risk Assessment BAB XI EdunexDokumen36 halamanRisk Assessment BAB XI Edunexpanji rahmanBelum ada peringkat
- Rangkuman Bab Vi (Itl)Dokumen15 halamanRangkuman Bab Vi (Itl)Firaz AzharBelum ada peringkat
- Buku Kontrol Lanjut Dan AplikasinyaDokumen137 halamanBuku Kontrol Lanjut Dan AplikasinyaRegita AmeliaBelum ada peringkat
- Reliability IndexDokumen20 halamanReliability IndexhafitjamaludinBelum ada peringkat
- Relia IDokumen33 halamanRelia IBaby PandaBelum ada peringkat
- Materi 5 Pak Nushron-1Dokumen13 halamanMateri 5 Pak Nushron-167D Wahyu IndahBelum ada peringkat
- Maintenance KLP 6Dokumen35 halamanMaintenance KLP 6Aldo PratamaBelum ada peringkat
- Kuliah 2 Manajemen Perawatan Dan PerbaikanDokumen26 halamanKuliah 2 Manajemen Perawatan Dan PerbaikanBlacklist XBelum ada peringkat
- Pemrograman Berorientasi Objek dengan Visual C#Dari EverandPemrograman Berorientasi Objek dengan Visual C#Penilaian: 3.5 dari 5 bintang3.5/5 (6)
- Mari Belajar Pemrograman Berorientasi Objek menggunakan Visual C# 6.0Dari EverandMari Belajar Pemrograman Berorientasi Objek menggunakan Visual C# 6.0Penilaian: 4 dari 5 bintang4/5 (16)
- Bab IiDokumen27 halamanBab Iirifqah umarBelum ada peringkat
- Content Laporan Kinerja Kementerian Esdm Tahun 2018Dokumen165 halamanContent Laporan Kinerja Kementerian Esdm Tahun 2018Jaya Energy TradingBelum ada peringkat
- Permen ESDM Nomor 16 Tahun 2020Dokumen492 halamanPermen ESDM Nomor 16 Tahun 2020mardi tandiburaBelum ada peringkat
- c51df Final 20210223 Bahan Permen Efisiensi Share 2Dokumen14 halamanc51df Final 20210223 Bahan Permen Efisiensi Share 2dika triBelum ada peringkat
- 88 Teknik Distribusi Tenaga Listrik Jilid 2Dokumen237 halaman88 Teknik Distribusi Tenaga Listrik Jilid 2Pelita HidupBelum ada peringkat
- 87 Teknik Distribusi Tenaga Listrik Jilid 1Dokumen133 halaman87 Teknik Distribusi Tenaga Listrik Jilid 1primas emeraldiBelum ada peringkat
- Teknik Distribusi Tenaga Listrik Jilid 3Dokumen120 halamanTeknik Distribusi Tenaga Listrik Jilid 3Open Knowledge and Education Book Programs86% (7)
- PTL 4 Latihan Soal Hubung SingkatDokumen17 halamanPTL 4 Latihan Soal Hubung Singkatdika triBelum ada peringkat
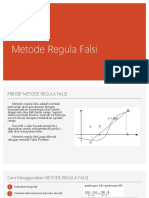
- Metode Regula Falsi - 2 TrueDokumen12 halamanMetode Regula Falsi - 2 Truedika triBelum ada peringkat
- Metode Newton Raphson - 1Dokumen16 halamanMetode Newton Raphson - 1dika triBelum ada peringkat
- Metode Biseksi - 2 TrueDokumen32 halamanMetode Biseksi - 2 Truedika tri100% (1)
- 3 3 10 1 10 20180108 PDFDokumen142 halaman3 3 10 1 10 20180108 PDFMade Dwi JuniarthaBelum ada peringkat
- 1880 108044 1 PBDokumen7 halaman1880 108044 1 PBdika triBelum ada peringkat
- Tugas Besar Struktur Baja IIDokumen200 halamanTugas Besar Struktur Baja IIdika triBelum ada peringkat