Anda mungkin juga menyukai
- 2a JST McCulloch Pitts NeuronDokumen51 halaman2a JST McCulloch Pitts NeuronTiurma CarolinaBelum ada peringkat
- Bab 7 Neuron - MC CUlloch Pitts PDFDokumen25 halamanBab 7 Neuron - MC CUlloch Pitts PDFNURAINI WIDYA NINGSIH 190534646415Belum ada peringkat
- AI - 5 Artificial Neural NetworksDokumen48 halamanAI - 5 Artificial Neural NetworksMuhammad Akbar HariyonoBelum ada peringkat
- JSTDokumen89 halamanJSTaliBelum ada peringkat
- Per 9 Fuzzy 1 PDFDokumen43 halamanPer 9 Fuzzy 1 PDFMuhammad Farhan FauzanBelum ada peringkat
- MODUL Teknik Digital 2022 FIXDokumen96 halamanMODUL Teknik Digital 2022 FIXAde aldi GantengBelum ada peringkat
- Pertemuan 13 - Pengantar Logika FuzzyDokumen32 halamanPertemuan 13 - Pengantar Logika FuzzyRasya NurmalaBelum ada peringkat
- Resistansi Dan Hukum OhmDokumen20 halamanResistansi Dan Hukum OhmnasmaBelum ada peringkat
- Pertemuan 2aDokumen70 halamanPertemuan 2aYoon ElfinitizefriendBelum ada peringkat
- Mengukur Suhu Dan Kelembaban Dengan Sensor DHT11Dokumen5 halamanMengukur Suhu Dan Kelembaban Dengan Sensor DHT11Reno Manoca KrisnantoBelum ada peringkat
- Jobsheet Sensor IR Dan Serial MonitorDokumen3 halamanJobsheet Sensor IR Dan Serial MonitorZainal AbidinBelum ada peringkat
- Materi Eko. X Smt.1 Revisi 2020Dokumen99 halamanMateri Eko. X Smt.1 Revisi 2020Olivia BalikpapanBelum ada peringkat
- Logika Fuzzy PDFDokumen39 halamanLogika Fuzzy PDFRisna FebriantiBelum ada peringkat
- 11 OK - Modul Elektronika Daya - S1 - 20191-1 PDFDokumen42 halaman11 OK - Modul Elektronika Daya - S1 - 20191-1 PDFtryvenavalentinetBelum ada peringkat
- Kontroversi MusikDokumen44 halamanKontroversi MusikMuhammad Fathoni Abu FaizBelum ada peringkat
- 6 Labsheet Sensor PIRDokumen11 halaman6 Labsheet Sensor PIRReyhan AdamBelum ada peringkat
- Fix Sop Lomba Masak FinalDokumen2 halamanFix Sop Lomba Masak FinalAnis hikmatulBelum ada peringkat
- Moga Jiwa Satria Mulia - Rancang Bangun Pemantau Kualitas Pencemaran Udara Menggunakan Sensor Di Industri Gula Berbasis - I - Android - IDokumen108 halamanMoga Jiwa Satria Mulia - Rancang Bangun Pemantau Kualitas Pencemaran Udara Menggunakan Sensor Di Industri Gula Berbasis - I - Android - IRobi MulyadiBelum ada peringkat
- Sensor PIRDokumen3 halamanSensor PIRMuhammad RuslyBelum ada peringkat
- Iman Dan Kufur Menurut Menurut Aliran KhawarijDokumen9 halamanIman Dan Kufur Menurut Menurut Aliran KhawarijIqbal TaufiqurrochmanBelum ada peringkat
- Sensor Suhu Dan Kelembaban DHT11Dokumen7 halamanSensor Suhu Dan Kelembaban DHT11Rizkiyan IsaBelum ada peringkat
- Sensor Suhu & KelembabanDokumen10 halamanSensor Suhu & KelembabanIQbàl Nak BhrocokBelum ada peringkat
- Fuzzy LogicDokumen39 halamanFuzzy LogicnuzulcoolBelum ada peringkat
- Modul ArduinoDokumen68 halamanModul Arduinoerdi abunawasBelum ada peringkat
- Prinsip Kerja Sensor RTDDokumen4 halamanPrinsip Kerja Sensor RTDTrianPrimadikaBelum ada peringkat
- Rizal Suhardiman F1c115098-Pengantar Ilmu SensorDokumen19 halamanRizal Suhardiman F1c115098-Pengantar Ilmu SensorRizal SuhardimanBelum ada peringkat
- Teknik Dasar ListrikDokumen33 halamanTeknik Dasar ListrikAnonymous mZJFhcBelum ada peringkat
- Mariyadi Sosiawan - 5215134347 - SKRIPSI 107 PDFDokumen186 halamanMariyadi Sosiawan - 5215134347 - SKRIPSI 107 PDFmekatronika smkn2tasikBelum ada peringkat
- Hukum OHMDokumen15 halamanHukum OHMjachle'sBelum ada peringkat
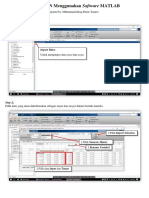
- Tutorial ANN Menggunakan Software MATLABDokumen9 halamanTutorial ANN Menggunakan Software MATLABMuhammad Idraq Ibnuts TsauriBelum ada peringkat
- Logika Fuzzy - YustiaDokumen100 halamanLogika Fuzzy - YustiahanafiajiBelum ada peringkat
- Engertian Waqaf Dan WashalDokumen24 halamanEngertian Waqaf Dan WashalnurislamiahBelum ada peringkat
- Sensor GASDokumen11 halamanSensor GASAnisa NurdiniBelum ada peringkat
- Diktat TrafoDokumen60 halamanDiktat TrafoZidan KanaiBelum ada peringkat
- Seminar Interfacing MikrokontrolerDokumen63 halamanSeminar Interfacing MikrokontrolerShidiq PermanaBelum ada peringkat
- Algoritma FuzzyDokumen33 halamanAlgoritma FuzzyLisyeBelum ada peringkat
- (Standar Daya PLN) Teknik Listrik Industri 3Dokumen222 halaman(Standar Daya PLN) Teknik Listrik Industri 3Eko Wahyu SetiawanBelum ada peringkat
- Pengukuran Listrik DinamisDokumen62 halamanPengukuran Listrik DinamisRoni EnjelaniBelum ada peringkat
- Modul Praktikum Pemograman 2020Dokumen68 halamanModul Praktikum Pemograman 2020real rin siregarBelum ada peringkat
- Analisis Intensitas Caanalisihaya Pada Area Produksi Terhadap Keselamatan Dan Kenyamanan Kerja Sesuai Dengan Standar PencahayaanDokumen10 halamanAnalisis Intensitas Caanalisihaya Pada Area Produksi Terhadap Keselamatan Dan Kenyamanan Kerja Sesuai Dengan Standar PencahayaanMuh JuniansyahBelum ada peringkat
- Pir OkDokumen6 halamanPir OkύπατίαBelum ada peringkat
- Beban Kerja MentalDokumen12 halamanBeban Kerja MentalUmmu Kamilah Kodrat IIBelum ada peringkat
- Dasar Teknik Elektro Secara UmumDokumen49 halamanDasar Teknik Elektro Secara UmumFadil SaragihBelum ada peringkat
- Modul Sensor Dan Transduser2Dokumen62 halamanModul Sensor Dan Transduser2yosferdi100% (1)
- Modul 2 SCADADokumen13 halamanModul 2 SCADARyan SinagaBelum ada peringkat
- Makalah Distribusi NormalDokumen16 halamanMakalah Distribusi NormalRizki NizCky 'Progress'Belum ada peringkat
- Teknik Transmisi Tenaga Listrik Jilid 1Dokumen201 halamanTeknik Transmisi Tenaga Listrik Jilid 1BelajarOnlineGratisBelum ada peringkat
- Neural Network (Ali Ridho)Dokumen41 halamanNeural Network (Ali Ridho)Lutfiyah N FadhilahBelum ada peringkat
- Jaringan Saraf CompressedDokumen30 halamanJaringan Saraf Compressedjojoj jkioBelum ada peringkat
- Artificial Neural NetworkDokumen59 halamanArtificial Neural NetworkDella Jesica BilqisBelum ada peringkat
- PERTEMUAN 10 Jaringan Saraf Tiruan (JST)Dokumen24 halamanPERTEMUAN 10 Jaringan Saraf Tiruan (JST)elstar11Belum ada peringkat
- Kecerdasan Tiruan Pertemuan 14 - CompressedDokumen52 halamanKecerdasan Tiruan Pertemuan 14 - Compressedhabzul21Belum ada peringkat
- Bab 8 Jaringan Syaraf TiruanDokumen17 halamanBab 8 Jaringan Syaraf TiruanEmonRivaiArganataBelum ada peringkat
- 2 - Jaringan Syaraf Tiruan (Artificial Neural Network)Dokumen14 halaman2 - Jaringan Syaraf Tiruan (Artificial Neural Network)502YORISSA SILVIANABelum ada peringkat
- Neural Network3 (Dasar Learning)Dokumen14 halamanNeural Network3 (Dasar Learning)Muhammad Iqbal .FBelum ada peringkat
- 2a McCulloch-Pitts NeuronDokumen49 halaman2a McCulloch-Pitts NeuronsiapayakkkBelum ada peringkat
- Kecerdasan Buatan 11 12Dokumen36 halamanKecerdasan Buatan 11 12Ridho Muhammad RamadhanBelum ada peringkat
- MODUL Praktikum PerceptronDokumen7 halamanMODUL Praktikum PerceptronNURHAFIFAH MATONDANGBelum ada peringkat
- Kopling 1Dokumen4 halamanKopling 1ramadhani prasetyaBelum ada peringkat
- Bab I Pendahuluan Velg DDokumen3 halamanBab I Pendahuluan Velg Dramadhani prasetyaBelum ada peringkat
- Materi 12Dokumen9 halamanMateri 12ramadhani prasetyaBelum ada peringkat
- Kopling 1Dokumen4 halamanKopling 1ramadhani prasetyaBelum ada peringkat
- Kuliah 9. Pemilihan Material Dan ProsesDokumen34 halamanKuliah 9. Pemilihan Material Dan ProsesYudda AzhariBelum ada peringkat
- Materi 13 TTLDokumen8 halamanMateri 13 TTLramadhani prasetyaBelum ada peringkat
- Modul 01Dokumen7 halamanModul 01ramadhani prasetyaBelum ada peringkat
- Materi 10Dokumen9 halamanMateri 10ramadhani prasetyaBelum ada peringkat
- Ensiklopedia SaranaDokumen8 halamanEnsiklopedia Saranaramadhani prasetyaBelum ada peringkat
- Bahan Ajar KompresorDokumen91 halamanBahan Ajar KompresorKingBelum ada peringkat