Anda mungkin juga menyukai
- Critical JurnalDokumen13 halamanCritical JurnalAgnes Erlita Distriani Patade50% (2)
- FilsafatDokumen8 halamanFilsafatRerendhutBelum ada peringkat
- Regresi Logistik SederhanaDokumen3 halamanRegresi Logistik Sederhanaannisa dwi fadzilahBelum ada peringkat
- Tugas Pape Teori Nola J PenderDokumen22 halamanTugas Pape Teori Nola J PenderMohamat MutajirBelum ada peringkat
- Tugas Makalah Teori Katherine KolobaDokumen10 halamanTugas Makalah Teori Katherine KolobaGracelia Herlince MakagansaBelum ada peringkat
- Terori OremDokumen16 halamanTerori Oremlya rahmaBelum ada peringkat
- Critical Appraisal Penelitian KuantitatifDokumen11 halamanCritical Appraisal Penelitian KuantitatifIsraBelum ada peringkat
- Analisa Jurnal Mutu Dengan PicotDokumen33 halamanAnalisa Jurnal Mutu Dengan PicotAnonymous l1MZrWBelum ada peringkat
- Falsafah Kelompok 5Dokumen10 halamanFalsafah Kelompok 5Mohammad RasadBelum ada peringkat
- Asuhan Keperawatan CA ColonDokumen26 halamanAsuhan Keperawatan CA ColonFaizatus ShafiyahBelum ada peringkat
- Instrument Pengkajian m1 Sampai m5-1Dokumen13 halamanInstrument Pengkajian m1 Sampai m5-1FebrianaBelum ada peringkat
- Kelompok Falsafah 1Dokumen21 halamanKelompok Falsafah 1Lutfi Dwi Acpa100% (1)
- LK1 - Kelompok V - Etika Keperawatan Terkait KepemimpinanDokumen19 halamanLK1 - Kelompok V - Etika Keperawatan Terkait KepemimpinanMawaddahBelum ada peringkat
- Revisi Proposal MiniDokumen58 halamanRevisi Proposal MiniJunita MaulinaBelum ada peringkat
- Kasus Dan SkenarioDokumen6 halamanKasus Dan SkenarioApri NurBelum ada peringkat
- Analisa Swot BaruDokumen13 halamanAnalisa Swot BaruRaniBelum ada peringkat
- Health Promotion NOLA J FENDER - ZADAM MARITADokumen19 halamanHealth Promotion NOLA J FENDER - ZADAM MARITAZadam MaritaBelum ada peringkat
- Cara Praktis Menentukan Uji StatistikDokumen5 halamanCara Praktis Menentukan Uji StatistikYeti Mareta100% (1)
- Tugas Riset KualitatifDokumen9 halamanTugas Riset KualitatifVHini De AngeloBelum ada peringkat
- RESEARCH CRITICAL PAPER QualitativeDokumen14 halamanRESEARCH CRITICAL PAPER Qualitativeika tukanBelum ada peringkat
- Analisa Hubungan Falsafah, Paradigma, Model Konseptual Kelompok 1Dokumen23 halamanAnalisa Hubungan Falsafah, Paradigma, Model Konseptual Kelompok 1Anisah WijayaBelum ada peringkat
- Mind Mapping CA ColonDokumen4 halamanMind Mapping CA ColonAgnes AdistyBelum ada peringkat
- Latihan (4) Penyajian Data & Interpretasi Regresi LinierDokumen1 halamanLatihan (4) Penyajian Data & Interpretasi Regresi LinierIda Ayu Mas NarayaniBelum ada peringkat
- Pelatihan Hand OverDokumen43 halamanPelatihan Hand OverRosalia SalmaBelum ada peringkat
- Lutfiani RosianaDokumen100 halamanLutfiani Rosianahani tuasikalBelum ada peringkat
- Kritisi Jurnal KualitatifDokumen5 halamanKritisi Jurnal KualitatifAnonymous l1MZrWBelum ada peringkat
- MAKALAH KEPERAWATAN UkbDokumen36 halamanMAKALAH KEPERAWATAN UkbPuskesmas penanggoan durenBelum ada peringkat
- Makalah Keperawatan Paliatif Belum SelesaiDokumen15 halamanMakalah Keperawatan Paliatif Belum SelesaiGede WiryawanBelum ada peringkat
- Perkembangan Sains Keperawatan Di Dunia Dan Di IndonesiaDokumen3 halamanPerkembangan Sains Keperawatan Di Dunia Dan Di Indonesianita indah pratiwiBelum ada peringkat
- Tugas 2 BAB KLP 9 Sain KeperawatanDokumen18 halamanTugas 2 BAB KLP 9 Sain KeperawatanNikeBelum ada peringkat
- Gabung ProposalDokumen33 halamanGabung ProposalWinda DarpianurBelum ada peringkat
- Take Home Filsafat IlmuDokumen6 halamanTake Home Filsafat IlmuAkbar ZhagtrisBelum ada peringkat
- C - Nur Eliyun - J230205001 (Mindmap 1)Dokumen2 halamanC - Nur Eliyun - J230205001 (Mindmap 1)Nur eliyunBelum ada peringkat
- Filosofi Gawat DaruratDokumen10 halamanFilosofi Gawat DaruratRahmawati PaongananBelum ada peringkat
- Analisis Univariat Data KategorikDokumen30 halamanAnalisis Univariat Data KategorikJihan ZakiyyahBelum ada peringkat
- Asuhan Keperawatan 1 UpipDokumen11 halamanAsuhan Keperawatan 1 UpipAlmaidatul ArismaBelum ada peringkat
- Perkembangan Peran Kepemimpinan Keperawatan Terkini Secara GlobalDokumen4 halamanPerkembangan Peran Kepemimpinan Keperawatan Terkini Secara GlobalkurniawatiBelum ada peringkat
- MEMILIH TEORI DALAM PENELITIAN KEPERAWATAN - 2022 - Update-1Dokumen42 halamanMEMILIH TEORI DALAM PENELITIAN KEPERAWATAN - 2022 - Update-1Wahyu NugraheniBelum ada peringkat
- Makalah PERENCANAAN MANAJEMEN KEPERAWATANDokumen10 halamanMakalah PERENCANAAN MANAJEMEN KEPERAWATANTunnisa RahmaBelum ada peringkat
- Prinsip EtikaDokumen2 halamanPrinsip EtikaTri Mulyana AgustinBelum ada peringkat
- Telaah Jurnal KMB BedahDokumen2 halamanTelaah Jurnal KMB BedahRachma AzizahBelum ada peringkat
- Middle Range TheoryDokumen29 halamanMiddle Range TheoryWimar AnugrahBelum ada peringkat
- MAKALAH KEPERAWATAN PALIATIF - KLP 5 - Teknik Penyampain Berita BurukDokumen28 halamanMAKALAH KEPERAWATAN PALIATIF - KLP 5 - Teknik Penyampain Berita BurukLiza Ermita100% (1)
- SRIEIRSYA ASWAN - Interprofessional Education (KDK1)Dokumen9 halamanSRIEIRSYA ASWAN - Interprofessional Education (KDK1)Srieirsya AswanBelum ada peringkat
- Tugas Kelompok 2 (MASALAH ETIK KEPERAWATAN)Dokumen25 halamanTugas Kelompok 2 (MASALAH ETIK KEPERAWATAN)Nyoman AriastitiBelum ada peringkat
- Latar Belakang Hambatan Mobilitas FisikDokumen3 halamanLatar Belakang Hambatan Mobilitas FisikNajwa fizraBelum ada peringkat
- Makalah Sim Project PoaDokumen23 halamanMakalah Sim Project PoaYusi nursiam100% (1)
- LTK-K1-Kelompok Filsafat Ilmu Campinha Bacote Model, Ginger and DavidhizarDokumen24 halamanLTK-K1-Kelompok Filsafat Ilmu Campinha Bacote Model, Ginger and DavidhizarAmiLia CandrasariBelum ada peringkat
- Ners Islami PRINTDokumen30 halamanNers Islami PRINTMilaBelum ada peringkat
- Laporan Awal Residensi Kmb-Kritis R-ParuDokumen32 halamanLaporan Awal Residensi Kmb-Kritis R-ParuMuhtar TeoBelum ada peringkat
- Intiative Big Data in NursingDokumen6 halamanIntiative Big Data in NursingRiska rahma safitriBelum ada peringkat
- Silabus Sains Keperawatan s2 2015Dokumen10 halamanSilabus Sains Keperawatan s2 2015rendhutBelum ada peringkat
- Kritik Jurnal Maternitas TantiDokumen15 halamanKritik Jurnal Maternitas TantiVebrycynk Vivin SlamaxBelum ada peringkat
- Implementasi Manajemen KeperawatanDokumen5 halamanImplementasi Manajemen KeperawatanWindaBelum ada peringkat
- DKJPS Pada BencanaDokumen97 halamanDKJPS Pada Bencanadesty s ikaBelum ada peringkat
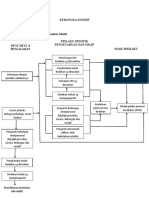
- Kerangka KonsepDokumen1 halamanKerangka KonsepLiana Warfandu100% (2)
- Contoh Poster Recruitment RSDokumen1 halamanContoh Poster Recruitment RSryanBelum ada peringkat
- Praktikum Komputasi Statistik 1 KOmetDokumen21 halamanPraktikum Komputasi Statistik 1 KOmetKomet RachmawansahBelum ada peringkat
- Analisa Bivariat Dan Analisa Multivariat KLP 2 b12 CDokumen42 halamanAnalisa Bivariat Dan Analisa Multivariat KLP 2 b12 CMade Dharmayanhi DharmayanhiBelum ada peringkat
- Hipotesis Dan Metode PenelitianDokumen8 halamanHipotesis Dan Metode PenelitiandwiBelum ada peringkat
- Sub RuangDokumen2 halamanSub RuangTsazumi NurSuciramadhaniBelum ada peringkat
- Proyeksi VektorDokumen4 halamanProyeksi VektorTsazumi NurSuciramadhaniBelum ada peringkat
- Matriks Kompleks PDFDokumen18 halamanMatriks Kompleks PDFTsazumi NurSuciramadhaniBelum ada peringkat
- Aljabar Pada Bilangan RealDokumen4 halamanAljabar Pada Bilangan RealTsazumi NurSuciramadhaniBelum ada peringkat
- Laporan 1 Statistika KesehatanDokumen27 halamanLaporan 1 Statistika KesehatanTsazumi NurSuciramadhaniBelum ada peringkat