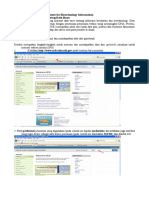
Anda mungkin juga menyukai
- Makalah Pemanfaatan GenbankDokumen21 halamanMakalah Pemanfaatan GenbankCamelia CitraBelum ada peringkat
- Laprak BLASTDokumen24 halamanLaprak BLASTMuhammadRezaPahlevi100% (2)
- Makalah BioinformatikaDokumen10 halamanMakalah BioinformatikaMaeBelum ada peringkat
- Vina Safitri - Laporan Pratikum Analisis Data SequencingDokumen13 halamanVina Safitri - Laporan Pratikum Analisis Data SequencingNurul Ilma SeptianiBelum ada peringkat
- 055 - Abdullah Khilmi - BIOTEKNOLOGI 6D - RESUME BAB 12Dokumen4 halaman055 - Abdullah Khilmi - BIOTEKNOLOGI 6D - RESUME BAB 12abdullah khilmiBelum ada peringkat
- Praktikum Ii Pengenalan Situs BioinformaDokumen14 halamanPraktikum Ii Pengenalan Situs BioinformaAnkerz15Belum ada peringkat
- Pengenalan NcbiDokumen35 halamanPengenalan Ncbitia100% (1)
- Lembar Kegiatan Saintifik AkramDokumen6 halamanLembar Kegiatan Saintifik AkramMuhammad AkramBelum ada peringkat
- Analisis Pensejajaran Urutan DNA/protein Dengan Blast SystemDokumen20 halamanAnalisis Pensejajaran Urutan DNA/protein Dengan Blast SystemSiti Rahmaningsih100% (1)
- BioinformatikaDokumen16 halamanBioinformatikaRisa AryantriBelum ada peringkat
- Pangkalan Data Dan Mencari Serta Membaca Data Biologi Pada Gene BankDokumen9 halamanPangkalan Data Dan Mencari Serta Membaca Data Biologi Pada Gene BankGerfindo WatugigirBelum ada peringkat
- Bioinformatics 1 NCBI Dan EBIDokumen4 halamanBioinformatics 1 NCBI Dan EBIalvianpBelum ada peringkat
- 325 513 1 SMDokumen7 halaman325 513 1 SMOI9 KHARISMA AULIA PUTRIBelum ada peringkat
- C - 4 - 230110200159 - Hafidz Ar Rashif HabibiDokumen5 halamanC - 4 - 230110200159 - Hafidz Ar Rashif Habibi159Hafidz Ar Rashif HabibiBelum ada peringkat
- Uas Bioinformatika-1Dokumen6 halamanUas Bioinformatika-1LAB CITO RSUDZABelum ada peringkat
- Windi Nopitasari 19032162 Laporan Analisis Data SequencingDokumen13 halamanWindi Nopitasari 19032162 Laporan Analisis Data SequencingSiska TanjungBelum ada peringkat
- Laporan Bioinformatika I PDFDokumen17 halamanLaporan Bioinformatika I PDFMuhammad Rizar Zakaria100% (1)
- LapRes Bioteknologi Farmasi - NCBI - Kelompok6 - Teori2DDokumen4 halamanLapRes Bioteknologi Farmasi - NCBI - Kelompok6 - Teori2DAlif SyahabBelum ada peringkat
- Bio Informa TikaDokumen21 halamanBio Informa TikaHana FailasufaBelum ada peringkat
- Laporan Bioinformatika I PDFDokumen17 halamanLaporan Bioinformatika I PDFSahar Sh.Belum ada peringkat
- Modul NCBI Introduction BLAST 3D 10 AprilDokumen16 halamanModul NCBI Introduction BLAST 3D 10 AprilsarijuicyBelum ada peringkat
- Analisis Sequen Dna Dengan Blast Dan Pengolahan Data Hasil Identifikasi Sekuen Menggunakan Program Bioinformatika Shinta Wahyu JuwitaDokumen8 halamanAnalisis Sequen Dna Dengan Blast Dan Pengolahan Data Hasil Identifikasi Sekuen Menggunakan Program Bioinformatika Shinta Wahyu JuwitaShinta Wahyu JuwitaBelum ada peringkat
- Mengenal NCBIDokumen22 halamanMengenal NCBIrony kundaBelum ada peringkat
- Laprak BlastDokumen11 halamanLaprak BlastintanBelum ada peringkat
- Pensejajaran Sekuen Virus H1N1 Dengan BlastDokumen19 halamanPensejajaran Sekuen Virus H1N1 Dengan BlastM Ivan Ariful FathoniBelum ada peringkat
- Laporan DM PERC Dinda Cahya Ayu PDokumen9 halamanLaporan DM PERC Dinda Cahya Ayu PAldhy AldhyBelum ada peringkat
- Analisis Data Hasil Sekuensing (Alignment Bioedit)Dokumen7 halamanAnalisis Data Hasil Sekuensing (Alignment Bioedit)ADimas Cahyaning Furqon0% (1)
- Mikro Identifikasi MolekulerDokumen13 halamanMikro Identifikasi MolekulerDana RahmatBelum ada peringkat
- Memanfaatkan DatabaseDokumen14 halamanMemanfaatkan DatabaseAbdul Rosyid Al MuhammadyBelum ada peringkat
- 13 Tugas Praktikum Hoirun NisaDokumen11 halaman13 Tugas Praktikum Hoirun NisaHoirun NisaBelum ada peringkat
- Pengenalan Ncbi - Kelompok 5gDokumen4 halamanPengenalan Ncbi - Kelompok 5gAstatinBelum ada peringkat
- Laporan Praktikum BiosistematikaDokumen12 halamanLaporan Praktikum BiosistematikanurulBelum ada peringkat
- P5 Bioinformatika Dan Pengenalan NCBI PDFDokumen13 halamanP5 Bioinformatika Dan Pengenalan NCBI PDFEustachia DiajengBelum ada peringkat
- LP - Biotek A2-1 Analisis BioinformatikaDokumen23 halamanLP - Biotek A2-1 Analisis BioinformatikaImtiyas AdzraBelum ada peringkat
- Tugas Baca Bioinformatika Biosel Winda Ayu Fietri (20177023)Dokumen4 halamanTugas Baca Bioinformatika Biosel Winda Ayu Fietri (20177023)windaBelum ada peringkat
- Laporan Praktikum Bioteknologi FarmasiDokumen27 halamanLaporan Praktikum Bioteknologi FarmasiAlfia SeptianaBelum ada peringkat
- Acara 3 BioinformatikaDokumen4 halamanAcara 3 Bioinformatikaanastasia sylviankaBelum ada peringkat
- Laporan Resmi Pengenalan Ncbi - Kelompok 8 (G) .Dokumen12 halamanLaporan Resmi Pengenalan Ncbi - Kelompok 8 (G) .Rama PratamaBelum ada peringkat
- TUGAS UTS RESUME BIOINFORMSTIKA - Salsabilla Shakira - B1A021008Dokumen4 halamanTUGAS UTS RESUME BIOINFORMSTIKA - Salsabilla Shakira - B1A021008Salsabilla ShakiraBelum ada peringkat
- Bab 3 Analisis GenomDokumen3 halamanBab 3 Analisis GenomMuhammad Arif SetiawanBelum ada peringkat
- M Bagus Firdaus - Lapsem Biomolekuler Materi 6Dokumen12 halamanM Bagus Firdaus - Lapsem Biomolekuler Materi 6Muhammad BagusBelum ada peringkat
- Pengenalan Website BioinformatikaDokumen6 halamanPengenalan Website BioinformatikaDevita SariBelum ada peringkat
- Percobaan 8 (Bioinformatika)Dokumen16 halamanPercobaan 8 (Bioinformatika)Wiratama NugrohoBelum ada peringkat
- Buku Petunjuk Drylab Biosel 2010Dokumen14 halamanBuku Petunjuk Drylab Biosel 2010AzhaBelum ada peringkat
- Laporan Bioinformatika Kel 5 LengkapDokumen59 halamanLaporan Bioinformatika Kel 5 LengkapYasintha Hapsari50% (2)
- BLASTDokumen12 halamanBLASTDwi Surya ArtieBelum ada peringkat
- Kelompk 1Dokumen7 halamanKelompk 1Gerfindo WatugigirBelum ada peringkat
- Klasifikasi MolekulerDokumen7 halamanKlasifikasi Molekulerchimy 15Belum ada peringkat
- MAKALAH Kelompok 1 Sistematika MikrobaDokumen10 halamanMAKALAH Kelompok 1 Sistematika MikrobaGerfindo WatugigirBelum ada peringkat
- Laporan P8 - Kelompok 4 Praktikum BiokimiaDokumen18 halamanLaporan P8 - Kelompok 4 Praktikum BiokimiaFirdaus ShofwanBelum ada peringkat
- Laporan Praktikum 1Dokumen11 halamanLaporan Praktikum 1Afifah SwadBelum ada peringkat
- TR 3 Bioinformatika - Widya KartikaDokumen4 halamanTR 3 Bioinformatika - Widya KartikaAhyana RehaniBelum ada peringkat
- Bioselmol Pengenalan NCBIDokumen19 halamanBioselmol Pengenalan NCBITyas SuryadiBelum ada peringkat
- BioinformatikaDokumen3 halamanBioinformatikaFaniMasaniBelum ada peringkat
- P. Biotek T3F - Kelompok 5 - BlastDokumen14 halamanP. Biotek T3F - Kelompok 5 - BlastCahyani DindaBelum ada peringkat
- Laporan BioinformatikaDokumen17 halamanLaporan Bioinformatikamayka putraBelum ada peringkat
- Laporan Praktikum Mikrobiologi II IdentifikasiDokumen36 halamanLaporan Praktikum Mikrobiologi II IdentifikasiRizka SukmasariBelum ada peringkat
- Laporan Praktikum Bioteknologi FarmasiDokumen13 halamanLaporan Praktikum Bioteknologi FarmasiApt Ulfi Mawadatur RohmahBelum ada peringkat
- Laporan 2Dokumen20 halamanLaporan 2devi eraBelum ada peringkat