Anda mungkin juga menyukai
- BigData PPATKDokumen24 halamanBigData PPATKRegina Irene Putri SharonBelum ada peringkat
- Penjelasan Teknik Purposive Sampling Lengkap Detail - Uji Statistik PDFDokumen1 halamanPenjelasan Teknik Purposive Sampling Lengkap Detail - Uji Statistik PDFBonifasius RichoBelum ada peringkat
- Pertemuan 5 - Materi PeramalanDokumen44 halamanPertemuan 5 - Materi Peramalanditppuzoom2Belum ada peringkat
- Silabus Analisis Proksimat GenapDokumen12 halamanSilabus Analisis Proksimat GenapYusriatiBelum ada peringkat
- MRPDokumen7 halamanMRPhafizhul HamdaBelum ada peringkat
- PPDT] Materi Tayang-SAP Navigation (1)Dokumen80 halamanPPDT] Materi Tayang-SAP Navigation (1)Wawan DarmantoBelum ada peringkat
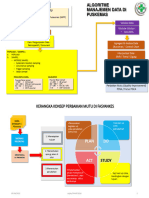
- Algoritma Manajemen Data FKTPDokumen2 halamanAlgoritma Manajemen Data FKTPradivan2022Belum ada peringkat
- Rencana PenilaianDokumen5 halamanRencana PenilaianWina Purnamasari DarmawanBelum ada peringkat
- 2 - 2 - Algoritma Dan Struktur Data PDFDokumen5 halaman2 - 2 - Algoritma Dan Struktur Data PDFmuhammad syaukaniBelum ada peringkat
- Statistik Untuk Pengambilan Keputusan BisnisDokumen17 halamanStatistik Untuk Pengambilan Keputusan BisnisRasya Kamila WahyudiBelum ada peringkat
- DiagramTulangIkanDokumen21 halamanDiagramTulangIkannandaBelum ada peringkat
- (MOV) Materi Tayang-SAP NavigationDokumen80 halaman(MOV) Materi Tayang-SAP Navigationhandy gunadiBelum ada peringkat
- FR-MMA.01.Rev.02-Mengorganisasikan Asesmen - MUK PDFDokumen12 halamanFR-MMA.01.Rev.02-Mengorganisasikan Asesmen - MUK PDFrickyBelum ada peringkat
- Slide 1Dokumen21 halamanSlide 1ASEP M.RAMDANBelum ada peringkat
- RPS PAJAK II [Drs SAPTO HENDRI BS., M.Si, WAHIDATUL HUSNAINI, INTAN RAKHMAWATI|JURUSAN AKUNTANSI FEB UNRAMDokumen4 halamanRPS PAJAK II [Drs SAPTO HENDRI BS., M.Si, WAHIDATUL HUSNAINI, INTAN RAKHMAWATI|JURUSAN AKUNTANSI FEB UNRAMCitra MentariBelum ada peringkat
- Set Instuksi Z-80Dokumen57 halamanSet Instuksi Z-80Fadil100% (1)
- Komputer Asas Ujian SpesifikasiDokumen2 halamanKomputer Asas Ujian SpesifikasiMOHD JAYDY EFIANSYAH BIN ALBERTO -JAYDYBelum ada peringkat
- Studi Penentuan Strategi Perawaatan Pada Mesin CNC Milling TerbaruDokumen29 halamanStudi Penentuan Strategi Perawaatan Pada Mesin CNC Milling TerbaruSamuel Putra TambunanBelum ada peringkat
- Sistem Informasi Manajemen Pertemuan 10Dokumen14 halamanSistem Informasi Manajemen Pertemuan 10T Henny Febriana HarumyBelum ada peringkat
- Slaid BengkelDokumen42 halamanSlaid BengkelOsman mohd harisBelum ada peringkat
- Bab 6 PeramalanDokumen23 halamanBab 6 PeramalanN DimasBelum ada peringkat
- Statistik PendidikanDokumen1 halamanStatistik PendidikanHusnah Tul KhatimahBelum ada peringkat
- Pengukuran Tingkat Kinerja KerjaDokumen25 halamanPengukuran Tingkat Kinerja Kerjaasal buatBelum ada peringkat
- Konsep Dasar BiostatistikDokumen9 halamanKonsep Dasar BiostatistikNur AdilaBelum ada peringkat
- Presentasi PDM - M.dani Julio GibranDokumen18 halamanPresentasi PDM - M.dani Julio GibranDani JulioBelum ada peringkat
- Flowchart MesinDokumen8 halamanFlowchart MesinFariz DimasBelum ada peringkat
- OPTIMASI BLUDDokumen42 halamanOPTIMASI BLUDIdo WidiBelum ada peringkat
- Machine LearningDokumen14 halamanMachine Learningbatista vebriartaBelum ada peringkat
- Overview of Lean Six SigmaDokumen96 halamanOverview of Lean Six SigmaYuliyanti BadrudinBelum ada peringkat
- Microprosesor 6Dokumen3 halamanMicroprosesor 6Frans MujiBelum ada peringkat
- Pengalaman Menerapkan Blud Rsud RDokumen43 halamanPengalaman Menerapkan Blud Rsud RdederuswandiBelum ada peringkat
- Pertemuan 2 - Konsep, Fungsi, Dan Peran StatistikDokumen59 halamanPertemuan 2 - Konsep, Fungsi, Dan Peran StatistikWisnu PrayogoBelum ada peringkat
- Sosialisasi Eam Up2k Reg MPNTDokumen28 halamanSosialisasi Eam Up2k Reg MPNTJunedjunaidyBelum ada peringkat
- Jadual Spesifikasi UjianDokumen1 halamanJadual Spesifikasi Ujianmarinda masdarBelum ada peringkat
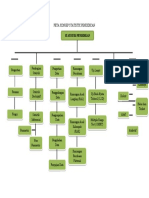
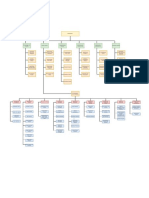
- SP2TP PUSKESMASDokumen28 halamanSP2TP PUSKESMASdesBelum ada peringkat
- 1 2 Dasar-PemrogramanDokumen6 halaman1 2 Dasar-Pemrograman4Berandal BerimanBelum ada peringkat
- SILABUSDokumen12 halamanSILABUSherino nasra100% (1)
- STRDATADokumen15 halamanSTRDATAGulbudin HekmatiarBelum ada peringkat
- FORM MMA KonvensionalDokumen14 halamanFORM MMA Konvensionalmurti sapto wahyudiBelum ada peringkat
- Matriks Analisis Materi Pembelajaran2Dokumen2 halamanMatriks Analisis Materi Pembelajaran2Darto1Belum ada peringkat
- STRDATADokumen15 halamanSTRDATAGulbudin HekmatiarBelum ada peringkat
- Proses Perkembangan ProyekDokumen1 halamanProses Perkembangan ProyekHelnyLalan100% (1)
- m3 Atropometri Kel 22 PtinDokumen31 halamanm3 Atropometri Kel 22 PtinEka Mutiara MaharaniBelum ada peringkat
- Implementasi Model Long Short Term Memory Pada Prediksi Harga Saham Bank BNIDokumen12 halamanImplementasi Model Long Short Term Memory Pada Prediksi Harga Saham Bank BNIShafrina NadiaBelum ada peringkat
- Makalah TEKNIS DAN PRAKTIS MRP PEMBAHASAN TEKNIK LOT SIZINGDokumen17 halamanMakalah TEKNIS DAN PRAKTIS MRP PEMBAHASAN TEKNIK LOT SIZINGDarmaBelum ada peringkat
- Blueprint & Template Soal OSCE UKAIDokumen18 halamanBlueprint & Template Soal OSCE UKAISeptian SuryoBelum ada peringkat
- Dashboard KINERJADokumen13 halamanDashboard KINERJAangelBelum ada peringkat
- Perencanaan Penganggaran Upt BLUDDokumen41 halamanPerencanaan Penganggaran Upt BLUDIdo WidiBelum ada peringkat
- Kriteria Design Jaringan DistribusiDokumen46 halamanKriteria Design Jaringan DistribusiAhmad MufliBelum ada peringkat
- PM PK SPIPDokumen21 halamanPM PK SPIPmydeasy78Belum ada peringkat
- Pertemuan 6 - Peramalan (1) MhsDokumen26 halamanPertemuan 6 - Peramalan (1) Mhssaya naanazBelum ada peringkat
- Materi Pelatihan Diklat Teknik & Manajemen 2020Dokumen154 halamanMateri Pelatihan Diklat Teknik & Manajemen 2020Ngadiyanto AntoBelum ada peringkat
- Menyusun Struktur Skala Upah Niken-1Dokumen28 halamanMenyusun Struktur Skala Upah Niken-1Eka IndahBelum ada peringkat
- Tugas RPL - Pdf.drawioDokumen1 halamanTugas RPL - Pdf.drawioM Sofyan Azzuhri NstBelum ada peringkat
- FORM MMA - Rev.01Dokumen24 halamanFORM MMA - Rev.01Agus SetyawanBelum ada peringkat
- TM 1 Konsep Dsar PDFDokumen25 halamanTM 1 Konsep Dsar PDFQueenyta SalsabilaBelum ada peringkat
- Kalkulus I SAPDokumen2 halamanKalkulus I SAPGila NoraBelum ada peringkat
- PT XYZ Business Process MappingDokumen7 halamanPT XYZ Business Process Mappinghse lazBelum ada peringkat
- Unikom - Muhammad Aldy Subagja - Bab 2Dokumen20 halamanUnikom - Muhammad Aldy Subagja - Bab 2NurdiAfribiBelum ada peringkat
- Pemanfaatan Business Intelligence Pada PDokumen11 halamanPemanfaatan Business Intelligence Pada Pdevil primoBelum ada peringkat
- Mengintip Ekosistem Big Data Di GojekDokumen5 halamanMengintip Ekosistem Big Data Di GojekDanie WiraBelum ada peringkat
- WDokumen4 halamanWNurdiAfribiBelum ada peringkat
- Sistem Data Warehouse Pada Pt. Semen PadDokumen13 halamanSistem Data Warehouse Pada Pt. Semen PadOvanBaruBelum ada peringkat
- Mengintip Ekosistem Big Data Di GojekDokumen5 halamanMengintip Ekosistem Big Data Di GojekDanie WiraBelum ada peringkat
- OPTIMALKAN BIG DATA UNTUK PENCARIAN PATTERNDokumen8 halamanOPTIMALKAN BIG DATA UNTUK PENCARIAN PATTERNyouleeahhhBelum ada peringkat
- Pamela SupermarketDokumen59 halamanPamela SupermarketNurdiAfribiBelum ada peringkat
- Simak Ui Tpa 2009Dokumen12 halamanSimak Ui Tpa 2009Shaka Shalahuddin Shantika Putra0% (1)
- Privasi Media SosialDokumen23 halamanPrivasi Media SosialNurdiAfribiBelum ada peringkat
- Simak UI Kemampuan IPS 2015Dokumen13 halamanSimak UI Kemampuan IPS 2015Muhtar DianBelum ada peringkat
- Gambaran Soal TPA OTO Bappenas 2014Dokumen55 halamanGambaran Soal TPA OTO Bappenas 2014sulaiman_itb91% (23)
- Pamela SupermarketDokumen59 halamanPamela SupermarketNurdiAfribiBelum ada peringkat
- Penerapan Data Mining Untuk Menentukan Strategi Penjualan Pada Toko Buku Gramedia PalembangDokumen25 halamanPenerapan Data Mining Untuk Menentukan Strategi Penjualan Pada Toko Buku Gramedia PalembangjoniBelum ada peringkat
- Tugas 3Dokumen9 halamanTugas 3NurdiAfribiBelum ada peringkat
- Simak Ui Tpa 2009Dokumen12 halamanSimak Ui Tpa 2009Shaka Shalahuddin Shantika Putra0% (1)
- Simak UI Kemampuan IPS 2015Dokumen13 halamanSimak UI Kemampuan IPS 2015Muhtar DianBelum ada peringkat
- Try Out 1 UIDokumen15 halamanTry Out 1 UIgrace_a7xBelum ada peringkat
- Tugas 1Dokumen2 halamanTugas 1NurdiAfribiBelum ada peringkat
- E-Book Bank Soal TpaDokumen54 halamanE-Book Bank Soal TpaOryza Sativani97% (36)
- Tugas 3Dokumen9 halamanTugas 3NurdiAfribiBelum ada peringkat
- Tugas Big Data in SportDokumen3 halamanTugas Big Data in SportNurdiAfribiBelum ada peringkat
- Presentation 1Dokumen10 halamanPresentation 1NurdiAfribiBelum ada peringkat
- Analisis Regresi PDFDokumen24 halamanAnalisis Regresi PDFputra scribdBelum ada peringkat





![PPDT] Materi Tayang-SAP Navigation (1)](https://imgv2-1-f.scribdassets.com/img/document/719878617/149x198/200ca6f2ab/1712202640?v=1)