Anda mungkin juga menyukai
- Leaflet Gagal GinjalDokumen2 halamanLeaflet Gagal GinjalRino PeterPanBelum ada peringkat
- Bunuh Diri Dan Euthanasia JADIDokumen14 halamanBunuh Diri Dan Euthanasia JADIHafis AmanattyasadiBelum ada peringkat
- Telaah KurikulumDokumen29 halamanTelaah KurikulumrayisekarsariBelum ada peringkat
- ASUHAN KEPERAWATAN KELUARGA TN M DENGAN GOUT ARTHRITIS PADA Ny I DI DUSUN PASAR SAPTU RT 02 RW 06 DESA CIKONENG WILAYAH KERJA UPTD KESEHATAN PUSKESMAS CIKONENG KABUPATEN CIAMIS TAHUN 2017 - 2 PDFDokumen23 halamanASUHAN KEPERAWATAN KELUARGA TN M DENGAN GOUT ARTHRITIS PADA Ny I DI DUSUN PASAR SAPTU RT 02 RW 06 DESA CIKONENG WILAYAH KERJA UPTD KESEHATAN PUSKESMAS CIKONENG KABUPATEN CIAMIS TAHUN 2017 - 2 PDFsiswantosprBelum ada peringkat
- Kelompok 2 Kesehatan Dan GiziDokumen11 halamanKelompok 2 Kesehatan Dan GiziApiah ApiahBelum ada peringkat
- Makalah Islam Kelompok6Dokumen15 halamanMakalah Islam Kelompok6Haira SesharisnaBelum ada peringkat
- Bab IiDokumen23 halamanBab IiBayuBelum ada peringkat
- Hubungan Peran GandaDokumen6 halamanHubungan Peran GandaAthala ZahwaBelum ada peringkat
- Sap SadariDokumen7 halamanSap Sadariedi purwantoBelum ada peringkat
- 1545 3085 1 SMDokumen9 halaman1545 3085 1 SMISRAWATIBelum ada peringkat
- Hamil Usia Tua 1Dokumen3 halamanHamil Usia Tua 1A-ghost RiderBelum ada peringkat
- Olahraga TradisionalDokumen7 halamanOlahraga TradisionalBungaBelum ada peringkat
- MakalahDokumen22 halamanMakalahAby WijayaBelum ada peringkat
- Teori Model KepKom WiwikDokumen13 halamanTeori Model KepKom Wiwiknono NonoBelum ada peringkat
- Yunita CA OvDokumen26 halamanYunita CA OvYunitha NabuasaBelum ada peringkat
- Makalah Bahasa ArabDokumen13 halamanMakalah Bahasa ArabLucfi AbimanyuBelum ada peringkat
- Makalah Tentang Profesi Pengembangan GuruDokumen21 halamanMakalah Tentang Profesi Pengembangan Gurumurphy 17Belum ada peringkat
- PKM KDokumen12 halamanPKM Knursulis96Belum ada peringkat
- CoverDokumen16 halamanCoverRanger PinkBelum ada peringkat
- Laporan Praktik Kerja Industri NewDokumen15 halamanLaporan Praktik Kerja Industri NewCendol DawetBelum ada peringkat
- Bab IiDokumen34 halamanBab IiMas PriyadhiBelum ada peringkat
- Makalah Bunuh Diri Dan Euthanasia Kel 6Dokumen11 halamanMakalah Bunuh Diri Dan Euthanasia Kel 6Imroatul WirasatiBelum ada peringkat
- Psiko Kelompok 3 Gangguan KecemasanDokumen18 halamanPsiko Kelompok 3 Gangguan KecemasanShafa Nada PratiwiBelum ada peringkat
- Gambar HewanDokumen16 halamanGambar HewanMuthia VaoraBelum ada peringkat
- Makalah Konsep FiqihDokumen15 halamanMakalah Konsep Fiqihrizka puspaning hanarBelum ada peringkat
- Makalah Administrasi PendidikanDokumen19 halamanMakalah Administrasi PendidikanFirman FadilahBelum ada peringkat
- Leaflet Kejang DemamDokumen2 halamanLeaflet Kejang DemamSuryaInsaniBelum ada peringkat
- Statistik Parametrik Dan Non-ParametrikDokumen9 halamanStatistik Parametrik Dan Non-ParametrikRianiBelum ada peringkat
- Tujuan Pendidikan IslamDokumen10 halamanTujuan Pendidikan IslamSiti SolihahBelum ada peringkat
- Hubungan Dukungan Sosial Teman Sebaya Dengan Resiliensi Pada Mahasiswa Rantau Yang Sedang Mengerjakan SkripsiDokumen27 halamanHubungan Dukungan Sosial Teman Sebaya Dengan Resiliensi Pada Mahasiswa Rantau Yang Sedang Mengerjakan SkripsiAnonymous pKe5IjgBelum ada peringkat
- Makalah Kel 1 - Teori PsikoanalisisDokumen27 halamanMakalah Kel 1 - Teori PsikoanalisisArneta NurfadilahBelum ada peringkat
- Raja NamrudDokumen5 halamanRaja NamrudnisyaBelum ada peringkat
- Memberikan Makan Per OralDokumen2 halamanMemberikan Makan Per OralIntan Setia BudiBelum ada peringkat
- Makalah PENGAWASDokumen10 halamanMakalah PENGAWASJhoy FalsonBelum ada peringkat
- Bab IiDokumen31 halamanBab IiHidayatul MualifaBelum ada peringkat
- Laporan Pendahuluan FebrisDokumen11 halamanLaporan Pendahuluan FebrisFaisalBelum ada peringkat
- Kel 1 - TAK Sosialisasi Sesi 1Dokumen10 halamanKel 1 - TAK Sosialisasi Sesi 1intanBelum ada peringkat
- Leaflet Demam TyphoidDokumen3 halamanLeaflet Demam TyphoidFitrah JelitaBelum ada peringkat
- Sertifikat Komputer 1Dokumen1 halamanSertifikat Komputer 1Renny Nur Astuti100% (1)
- Sap Pengenalan Diabetes Mellitus (Komunitas)Dokumen12 halamanSap Pengenalan Diabetes Mellitus (Komunitas)setiawandalimarthaBelum ada peringkat
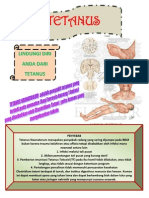
- Poster TetanusDokumen1 halamanPoster TetanusAlex RahmaBelum ada peringkat
- Askep Trauma AbdomenDokumen22 halamanAskep Trauma Abdomenwiyanda 18018Belum ada peringkat
- Askep Trauma AbdomenDokumen24 halamanAskep Trauma AbdomenClausewitz Kla MasalaBelum ada peringkat
- Makalah Pendidikan Anak Usia DiniDokumen5 halamanMakalah Pendidikan Anak Usia DiniSangkala PeaceBelum ada peringkat
- Contoh Laporan Prakerin Teknik Mesin 01Dokumen24 halamanContoh Laporan Prakerin Teknik Mesin 01adhybrusBelum ada peringkat
- Makalah Keterampilan Dasar MengajarDokumen25 halamanMakalah Keterampilan Dasar MengajarHubbi MilatiBelum ada peringkat
- Makalah Kel 5 Kehamilan RemajaDokumen12 halamanMakalah Kel 5 Kehamilan RemajaSintaBelum ada peringkat
- Makalah Bimbingan Konseling Agama Islam Buku 2.Dokumen52 halamanMakalah Bimbingan Konseling Agama Islam Buku 2.checheBelum ada peringkat
- Makalah Pengembangan Kurikulum PaiDokumen21 halamanMakalah Pengembangan Kurikulum Painimah lailaBelum ada peringkat
- Soal InflasiDokumen2 halamanSoal InflasiWidiaBelum ada peringkat
- Mengenal Rangka Tubuh ManusiaDokumen7 halamanMengenal Rangka Tubuh ManusiaPrayudiSetiawanIgmBelum ada peringkat
- Pengaruh Pendidikan Agama Islam Yang Diberikan Orang TuaDokumen135 halamanPengaruh Pendidikan Agama Islam Yang Diberikan Orang TuaHarry D. FauziBelum ada peringkat
- Satuan Acara Penyuluhan SadariDokumen10 halamanSatuan Acara Penyuluhan SadariSiska Ayu FitriBelum ada peringkat
- SAP - Pneumonia RSSADokumen10 halamanSAP - Pneumonia RSSAAnny DanggaBelum ada peringkat
- Manajemen Pembelajaran Pendidikan Agama Islam Di Perguruan TinggiDokumen18 halamanManajemen Pembelajaran Pendidikan Agama Islam Di Perguruan TinggiImron UbaidillahBelum ada peringkat
- Laporan Artikel Pengaruh Gadget Terhadap Perkembangan Anak Karya Milana Abdillah SubarkahDokumen12 halamanLaporan Artikel Pengaruh Gadget Terhadap Perkembangan Anak Karya Milana Abdillah SubarkahtuyuliantiBelum ada peringkat
- Makalah Statistik Pendidikan Kelompok 2 - PGSD - Semester 5aDokumen37 halamanMakalah Statistik Pendidikan Kelompok 2 - PGSD - Semester 5aDirgantara officialBelum ada peringkat
- MAKALAH Statistik KLP 1Dokumen17 halamanMAKALAH Statistik KLP 1Julia KarmantoBelum ada peringkat
- 05-Makalah Ukuran Gejala Pusat - Statistika DasarDokumen15 halaman05-Makalah Ukuran Gejala Pusat - Statistika DasarLullaa BabyBelum ada peringkat
- KLP 1 Metode Deskriptif Dan Uji NormalitasDokumen37 halamanKLP 1 Metode Deskriptif Dan Uji NormalitasI Gede Putra Sainan Jaya100% (1)
- Materi 5 - Penyusunan Logbook Dan Dokumentasi KegiatanDokumen32 halamanMateri 5 - Penyusunan Logbook Dan Dokumentasi KegiatanMusa AlfaBelum ada peringkat
- Materi 4 - Penyusunan Program, Pelaksanaan Dan Pelaporan KKN TematikDokumen17 halamanMateri 4 - Penyusunan Program, Pelaksanaan Dan Pelaporan KKN TematikMusa AlfaBelum ada peringkat
- Materi 3 - Pemanfaatan Pekarangan Dalam Upaya Menyiapkan Ketahanan Pangan KeluargaDokumen27 halamanMateri 3 - Pemanfaatan Pekarangan Dalam Upaya Menyiapkan Ketahanan Pangan KeluargaMusa AlfaBelum ada peringkat
- Materi 1 - Operasional KKN UMK Tahun 2022Dokumen16 halamanMateri 1 - Operasional KKN UMK Tahun 2022Musa AlfaBelum ada peringkat
- Materi 2 - Stunting Dan PencegahannyaDokumen21 halamanMateri 2 - Stunting Dan PencegahannyaMusa AlfaBelum ada peringkat