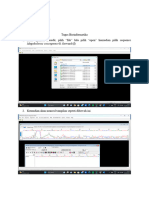
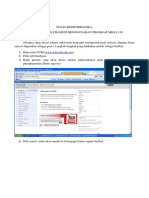
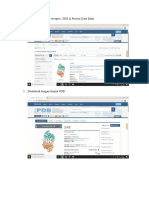
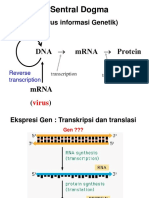
Anda mungkin juga menyukai
- BioinfoDokumen5 halamanBioinfoRika Rahma PutriBelum ada peringkat
- RAPHYDOPHYTADokumen12 halamanRAPHYDOPHYTANaomi Berthi Yonindhi50% (2)
- Cara Mengedit Sequence Dengan BioeditDokumen14 halamanCara Mengedit Sequence Dengan Bioeditmuhammad choirul badriBelum ada peringkat
- BIOINFORMATIKADokumen15 halamanBIOINFORMATIKAAsuler Weleh Weleh100% (3)
- Tugas MSA Megabalanus Coccopoma - Salsabilla Shakira - B1A021008 - Kelas ADokumen18 halamanTugas MSA Megabalanus Coccopoma - Salsabilla Shakira - B1A021008 - Kelas ASalsabilla ShakiraBelum ada peringkat
- Tutorial BioinformatikaDokumen36 halamanTutorial BioinformatikaAde HabibieBelum ada peringkat
- Rangkuman BioinformatikaDokumen2 halamanRangkuman BioinformatikaRenata PrimasariBelum ada peringkat
- Bioedit Dan MegaDokumen12 halamanBioedit Dan MegaShanty Veronica SijabatBelum ada peringkat
- Cara Kerja Mega 6Dokumen10 halamanCara Kerja Mega 6ita rianiBelum ada peringkat
- Bioinformatika 4Dokumen9 halamanBioinformatika 4pwd bambangBelum ada peringkat
- Bio EditDokumen3 halamanBio EditDevi PratiwiBelum ada peringkat
- Protokol Pelatihan BioinformatikaDokumen21 halamanProtokol Pelatihan BioinformatikaI EBelum ada peringkat
- Tutorial Analisis Filogenetik Menggunakan Software MegaDokumen12 halamanTutorial Analisis Filogenetik Menggunakan Software MegaKepala LabBelum ada peringkat
- E1A0201108 - Zahratul Ainun - T1 BioinformatikaDokumen3 halamanE1A0201108 - Zahratul Ainun - T1 Bioinformatikasundussepia17Belum ada peringkat
- Tutorial Aplikasi Soal Dan Maqra Musabaqah RingkasDokumen4 halamanTutorial Aplikasi Soal Dan Maqra Musabaqah RingkasInfo Kanwil Kemenag Prov. BantenBelum ada peringkat
- TKJ ImeldaDokumen19 halamanTKJ ImeldaFaizal NiodeBelum ada peringkat
- Septiani Nurcahyanti - 24020221140090 - Lapres Acara 4 BioinformatikaDokumen14 halamanSeptiani Nurcahyanti - 24020221140090 - Lapres Acara 4 BioinformatikaSeptiani NurcahyantiBelum ada peringkat
- Hasrilia Beskara - 1713441008 - Picp17 - Makalah Aplikasi Avogadro PDFDokumen11 halamanHasrilia Beskara - 1713441008 - Picp17 - Makalah Aplikasi Avogadro PDFHasrilia BeskaraBelum ada peringkat
- DOCKINGDokumen8 halamanDOCKINGNovita ekaBelum ada peringkat
- Menggunakanjsondandatabase MysqlDokumen35 halamanMenggunakanjsondandatabase MysqlRizki AstutiBelum ada peringkat
- Modul 4 BioinformatikaDokumen5 halamanModul 4 BioinformatikaEvan Sugiarto AfilBelum ada peringkat
- Kelompok 1 - Laporan Praktikum Sequencing - Biokimia - PSPB C 2019Dokumen6 halamanKelompok 1 - Laporan Praktikum Sequencing - Biokimia - PSPB C 2019Anggi Natasya100% (1)
- Laporan Resmi Praktikum Gene Bank Ncbi - Kelompok 6 - T2CDokumen22 halamanLaporan Resmi Praktikum Gene Bank Ncbi - Kelompok 6 - T2CMarista Nur cahyaniBelum ada peringkat
- Tutorial Acara 1Dokumen15 halamanTutorial Acara 1SatrioBelum ada peringkat
- Laporan Praktikum Molecular DockingDokumen14 halamanLaporan Praktikum Molecular DockingIsnainiBelum ada peringkat
- Lembar Kerja Peserta DidikDokumen7 halamanLembar Kerja Peserta Didikiyus walupiBelum ada peringkat
- Digdo 9178 Bioinfo Pak SyaifurDokumen22 halamanDigdo 9178 Bioinfo Pak SyaifurDigdo SudigyoBelum ada peringkat
- Jobsheet Sistem Lelang Part 3 PBODokumen22 halamanJobsheet Sistem Lelang Part 3 PBOSari AzhariyahBelum ada peringkat
- B2 1 1908010096 Khairunnisa Lapres p2Dokumen14 halamanB2 1 1908010096 Khairunnisa Lapres p2Khairun nisaBelum ada peringkat
- Analisis Pohon FilogeniDokumen12 halamanAnalisis Pohon FilogeniSiti NovianaBelum ada peringkat
- Laporan Praktikum BiosistematikaDokumen12 halamanLaporan Praktikum BiosistematikanurulBelum ada peringkat
- Pengenalan Aplikasi Vector NTI FiksDokumen20 halamanPengenalan Aplikasi Vector NTI FiksmarisaBelum ada peringkat
- LKPD Per. 1 Dan 2Dokumen8 halamanLKPD Per. 1 Dan 2farhannajman220107Belum ada peringkat
- Resume 6Dokumen9 halamanResume 6004Nelly JuentiBelum ada peringkat
- Nelly Juenti - Resume 6 - Kelompok 2Dokumen9 halamanNelly Juenti - Resume 6 - Kelompok 2004Nelly JuentiBelum ada peringkat
- In Silico (Desain Primer)Dokumen5 halamanIn Silico (Desain Primer)BalqisArcheNofinska100% (1)
- Cara Membuat Crack Menggunakan Software - Tip Trik ComputerDokumen9 halamanCara Membuat Crack Menggunakan Software - Tip Trik ComputerAcher AcherBelum ada peringkat
- Modul-Sesi2 1Dokumen6 halamanModul-Sesi2 1Hilman TaufiqBelum ada peringkat
- Manual Pengguna - Pemasangan GPKI - AGENT 3.0 Release 1.0.0.1-MACOS PDFDokumen9 halamanManual Pengguna - Pemasangan GPKI - AGENT 3.0 Release 1.0.0.1-MACOS PDFRashdan MamatBelum ada peringkat
- Tugas Embedded Operating System - Demo Aplikasi Berbasis TinyOSDokumen13 halamanTugas Embedded Operating System - Demo Aplikasi Berbasis TinyOSarifatiaddiyaaniBelum ada peringkat
- Aplikasi AvogadroDokumen13 halamanAplikasi AvogadroAgustaaBelum ada peringkat
- Tugas JDK - JCreator - CodingDokumen19 halamanTugas JDK - JCreator - Codingparasurama kingsmanBelum ada peringkat
- AvogadroDokumen10 halamanAvogadroratnasari2223Belum ada peringkat
- Zahfal Zuhdi 13201091 Laporan M3 Kelompok ODokumen9 halamanZahfal Zuhdi 13201091 Laporan M3 Kelompok OZahfal ZuhdiBelum ada peringkat
- Panduan Install ESETDokumen24 halamanPanduan Install ESETZhakky ArrizalBelum ada peringkat
- Tutorial Menggunakan Aplikasi Kimia AvogadroDokumen5 halamanTutorial Menggunakan Aplikasi Kimia AvogadroFita Candra SBelum ada peringkat
- Kegunaan KeygenDokumen5 halamanKegunaan KeygenPengeran Tak BerdosaBelum ada peringkat
- B2 - 3 - 1908010108 - Muhammad Naufal Rabbani - P2Dokumen14 halamanB2 - 3 - 1908010108 - Muhammad Naufal Rabbani - P2siti salma haniyyahBelum ada peringkat
- Susunan Laporan Makalah Wordpress FixDokumen27 halamanSusunan Laporan Makalah Wordpress FixCah KerenBelum ada peringkat
- Uts Bioinformatika Citra InnosensiaDokumen27 halamanUts Bioinformatika Citra InnosensiaCitra InnosensiaBelum ada peringkat
- Modul Praktikum KimedDokumen34 halamanModul Praktikum KimedVincentBelum ada peringkat
- Jobsheet Sistem Lelang Part 5 PBODokumen12 halamanJobsheet Sistem Lelang Part 5 PBOSari AzhariyahBelum ada peringkat
- Panduan Molecular Docking Autodock 4.0Dokumen17 halamanPanduan Molecular Docking Autodock 4.0alisia difianaBelum ada peringkat
- Sekuensing DNADokumen13 halamanSekuensing DNAAdhara ZephyraBelum ada peringkat
- DokingDokumen29 halamanDokingAnjali WidhiyaniBelum ada peringkat
- Keamanan Jaringan 2Dokumen49 halamanKeamanan Jaringan 2Achmad ZakariaBelum ada peringkat
- Bab II WASP Computer InterfaceDokumen33 halamanBab II WASP Computer InterfaceMeity AnggrainiBelum ada peringkat
- Manual+Aplikasi+Proktor+2023 202352 CompressedDokumen11 halamanManual+Aplikasi+Proktor+2023 202352 CompressedZidan Attarmasie AlaminBelum ada peringkat
- 22-K13-Pemrograman DasarDokumen23 halaman22-K13-Pemrograman DasarNur AdelBelum ada peringkat
- Panduan Menginstall Windows Vista Sp2 Edisi Bahasa InggrisDari EverandPanduan Menginstall Windows Vista Sp2 Edisi Bahasa InggrisPenilaian: 5 dari 5 bintang5/5 (1)
- IEP KesyaDokumen3 halamanIEP KesyaNaomi Berthi YonindhiBelum ada peringkat
- IEP Juna 2022Dokumen5 halamanIEP Juna 2022Naomi Berthi YonindhiBelum ada peringkat
- Skrining PranaDokumen6 halamanSkrining PranaNaomi Berthi YonindhiBelum ada peringkat
- Skrining AlonaDokumen8 halamanSkrining AlonaNaomi Berthi YonindhiBelum ada peringkat
- Hasil Assesmen KeysaDokumen6 halamanHasil Assesmen KeysaNaomi Berthi YonindhiBelum ada peringkat
- Iep JasonDokumen4 halamanIep JasonNaomi Berthi YonindhiBelum ada peringkat
- IEP Prana 2022Dokumen3 halamanIEP Prana 2022Naomi Berthi YonindhiBelum ada peringkat
- Iep AaronDokumen4 halamanIep AaronNaomi Berthi YonindhiBelum ada peringkat
- Undangan Peserta Kurikulum 2013 Tahun 2022Dokumen2 halamanUndangan Peserta Kurikulum 2013 Tahun 2022Naomi Berthi YonindhiBelum ada peringkat
- Isi Kurikulum. REV ABA4Dokumen32 halamanIsi Kurikulum. REV ABA4Naomi Berthi YonindhiBelum ada peringkat
- Assessment JevanDokumen6 halamanAssessment JevanNaomi Berthi YonindhiBelum ada peringkat
- FistumDokumen12 halamanFistumNaomi Berthi YonindhiBelum ada peringkat
- Laporan PertanggungjawabanDokumen4 halamanLaporan PertanggungjawabanNaomi Berthi YonindhiBelum ada peringkat
- 2 PBDokumen10 halaman2 PBAi herlinaBelum ada peringkat
- Modul Ajar MuharramDokumen6 halamanModul Ajar MuharramNaomi Berthi YonindhiBelum ada peringkat
- BATANG Baru LagiDokumen3 halamanBATANG Baru LagiNaomi Berthi YonindhiBelum ada peringkat
- Diversitas Dan Sejarah Klasifikasi ProtistaDokumen25 halamanDiversitas Dan Sejarah Klasifikasi ProtistaNaomi Berthi YonindhiBelum ada peringkat
- Potensi Daun Beluntas-MRSADokumen61 halamanPotensi Daun Beluntas-MRSAIdriz Aidy IdrizBelum ada peringkat
- BAB II Hormon Hipotalamus Dan HipofisisDokumen41 halamanBAB II Hormon Hipotalamus Dan HipofisisnanangBelum ada peringkat
- Asam SalisilatDokumen10 halamanAsam SalisilatNaomi Berthi Yonindhi100% (1)
- Perkembangan Umbi Pada TumbuhanDokumen19 halamanPerkembangan Umbi Pada TumbuhanNaomi Berthi YonindhiBelum ada peringkat
- Bab IiDokumen27 halamanBab IiNaomi Berthi YonindhiBelum ada peringkat
- Acara 2 Ini PentingDokumen28 halamanAcara 2 Ini PentingNaomi Berthi YonindhiBelum ada peringkat
- Fisiologi Hewan Air RESPIRASIDokumen20 halamanFisiologi Hewan Air RESPIRASIferenrikaBelum ada peringkat
- Kontrol Sekresi Hormon Endokrin Pada HipotalamusDokumen20 halamanKontrol Sekresi Hormon Endokrin Pada HipotalamusNaomi Berthi YonindhiBelum ada peringkat
- Gene Expression - TranscriptionDokumen24 halamanGene Expression - TranscriptionZakiyah RamadanyBelum ada peringkat
- Praktikum Ii Pengenalan Situs BioinformaDokumen14 halamanPraktikum Ii Pengenalan Situs BioinformaAnkerz15Belum ada peringkat
- BacillariophytaDokumen3 halamanBacillariophytaNaomi Berthi YonindhiBelum ada peringkat