Anda mungkin juga menyukai
- Tugas 2 HipotesisDokumen14 halamanTugas 2 HipotesisNur halizaBelum ada peringkat
- BOOK - Tritjahjo Danny - Ragam Dan Prosedur Penelitian Tindakan - Bab 5Dokumen8 halamanBOOK - Tritjahjo Danny - Ragam Dan Prosedur Penelitian Tindakan - Bab 5HiyahBelum ada peringkat
- Hipotesis PenelitianDokumen3 halamanHipotesis PenelitiandiyanBelum ada peringkat
- BOOK - Danny Tritjahjo - Penelitian Inferensial Dalam Bidang Pendidikan - Bab 3Dokumen10 halamanBOOK - Danny Tritjahjo - Penelitian Inferensial Dalam Bidang Pendidikan - Bab 3Nabiel Putra AdamBelum ada peringkat
- Goresan Kuliah - HipotesisDokumen7 halamanGoresan Kuliah - HipotesisEL-nina Liebt U VaterBelum ada peringkat
- STATISTIK-hipotesis PenelitianDokumen11 halamanSTATISTIK-hipotesis PenelitianE-dho ArhamedhoBelum ada peringkat
- Hipotesis Penelitian Dan AsumsiDokumen14 halamanHipotesis Penelitian Dan AsumsiIlmiatul mufidahBelum ada peringkat
- Pengertian Uji Hipotesis Dan JenisDokumen8 halamanPengertian Uji Hipotesis Dan Jenisasih_96wulanBelum ada peringkat
- Pengertian HipotensisDokumen7 halamanPengertian HipotensisAriBelum ada peringkat
- Rangkuman Ke-1 Haerumnisah Rauf 210903502025 Statistika InferensialDokumen10 halamanRangkuman Ke-1 Haerumnisah Rauf 210903502025 Statistika InferensialNabilla TulilmiBelum ada peringkat
- Hipotesis PenelitianDokumen4 halamanHipotesis PenelitianAnabell AlpenliebeBelum ada peringkat
- OPTIMALKAN HUBUNGAN VARIABELDokumen13 halamanOPTIMALKAN HUBUNGAN VARIABELI K WirawanBelum ada peringkat
- 29 - Puji Rahayu (Praktikum 8 - Konsep Uji Hipotesis)Dokumen10 halaman29 - Puji Rahayu (Praktikum 8 - Konsep Uji Hipotesis)Puji RahayuBelum ada peringkat
- Hipotesis PenelitianDokumen11 halamanHipotesis PenelitianDedhy JadulBelum ada peringkat
- HipotesisDokumen9 halamanHipotesisSumar Hadi SantosoBelum ada peringkat
- Jawaban Soal MPP No 1 Bagian D Dan EDokumen3 halamanJawaban Soal MPP No 1 Bagian D Dan ENurani MasyitaBelum ada peringkat
- Pengertian HipotesisDokumen6 halamanPengertian HipotesisMuhammad Arief HarvityantoBelum ada peringkat
- HIPOTESIS PENELITIANDokumen9 halamanHIPOTESIS PENELITIANirnaBelum ada peringkat
- HipotesisDokumen2 halamanHipotesisyusufmuhalwy98Belum ada peringkat
- Hipotesis PenelitianDokumen13 halamanHipotesis PenelitianFatwa KasipahuBelum ada peringkat
- Kel.10 Hipotesis Dan Pertanyaan PenelitianDokumen9 halamanKel.10 Hipotesis Dan Pertanyaan PenelitianAprilya RBelum ada peringkat
- HipotesisDokumen11 halamanHipotesisFajar Pra WicxBelum ada peringkat
- Resume005 MPDokumen10 halamanResume005 MPThrana DonaBelum ada peringkat
- STATISTIKADokumen9 halamanSTATISTIKABoim LebonBelum ada peringkat
- Bab 1Dokumen14 halamanBab 1Hardiyanti AnthyBelum ada peringkat
- Makalah HipotesisDokumen9 halamanMakalah HipotesisDani Anugrah PratamaBelum ada peringkat
- Metopel Blum SiapDokumen8 halamanMetopel Blum Siapsartika yuliantiBelum ada peringkat
- Materi Kerangka Pikir Dan Hipotesis PDFDokumen4 halamanMateri Kerangka Pikir Dan Hipotesis PDFElsya SalsabillaBelum ada peringkat
- Pengertian HipotesisDokumen12 halamanPengertian HipotesisAprilia Anggraeni100% (1)
- Hipotesis PenelitianDokumen20 halamanHipotesis PenelitianMuhammad Sobirin100% (1)
- Hipotesis PenelitianDokumen6 halamanHipotesis PenelitianChie Afrida PutriBelum ada peringkat
- HipotesisDokumen10 halamanHipotesisGriffin WalkerBelum ada peringkat
- KONSEP HIPOTESIS DAN DESAIN PENELITIANDokumen17 halamanKONSEP HIPOTESIS DAN DESAIN PENELITIANSri RahayuBelum ada peringkat
- Pengertian HipotesesDokumen4 halamanPengertian HipotesesWahzu PurwantoBelum ada peringkat
- Merumuskan Hipotesis Dan Memilih PendekatanDokumen33 halamanMerumuskan Hipotesis Dan Memilih PendekatanKo KholisBelum ada peringkat
- HIPOTESISDokumen8 halamanHIPOTESIStrueamourBelum ada peringkat
- HIPOTESISDokumen10 halamanHIPOTESISnurmailisBelum ada peringkat
- Makalah Tentang Pengujian Hipotesis FixDokumen12 halamanMakalah Tentang Pengujian Hipotesis FixErinaBelum ada peringkat
- HIPOTESISDokumen20 halamanHIPOTESISTriimah WahyuniBelum ada peringkat
- HipotesisDokumen9 halamanHipotesisSyahwa Ramadhan100% (2)
- Kerangka KonsepDokumen5 halamanKerangka KonsepFitry RamadhanBelum ada peringkat
- Makalah Merumuskan Hipotesis DLM PenelitianDokumen5 halamanMakalah Merumuskan Hipotesis DLM PenelitianratnaBelum ada peringkat
- Hipotesis PenelitianDokumen5 halamanHipotesis PenelitianNurina AprilyaBelum ada peringkat
- HipotesisDokumen22 halamanHipotesisSerena Titan100% (1)
- Pertemuan III - Kajian Literatur-Hipotesis-Sumber DataDokumen18 halamanPertemuan III - Kajian Literatur-Hipotesis-Sumber Dataestu kaniraBelum ada peringkat
- HipotesisDokumen10 halamanHipotesisAnha Yulia RahmaBelum ada peringkat
- Makalah HipotesisDokumen18 halamanMakalah Hipotesisferi ferBelum ada peringkat
- Makalah Pengujian Hipotesis Statsitik FarmasiDokumen16 halamanMakalah Pengujian Hipotesis Statsitik Farmasiaipriutami0% (1)
- HIPOTESISDokumen11 halamanHIPOTESISAndi IkhsanBelum ada peringkat
- Hipotesis FadilaDokumen5 halamanHipotesis FadilaFhadilla PutraBelum ada peringkat
- Hipotesis Dan Pertanyaan PenelitianDokumen10 halamanHipotesis Dan Pertanyaan PenelitianIendah HaqqunBelum ada peringkat
- AlfredSaputra-003 21 13 002-PertemuankelimaDokumen3 halamanAlfredSaputra-003 21 13 002-PertemuankelimaAlfred SaputraBelum ada peringkat
- Hipotesis 69 78Dokumen10 halamanHipotesis 69 78SintyaBelum ada peringkat
- Pertemuan Ke 9 MetopelDokumen26 halamanPertemuan Ke 9 MetopelDe ArmaYanti SyamBelum ada peringkat
- Pertemuan 9.docDokumen16 halamanPertemuan 9.docSaskia Nur JanahBelum ada peringkat
- Makalah Statistik Kel 3 RevisiDokumen8 halamanMakalah Statistik Kel 3 RevisiMusdalifa PybBelum ada peringkat
- Pengertian dan Jenis-Jenis HipotesisDokumen10 halamanPengertian dan Jenis-Jenis HipotesisIndah Kusuma DewiBelum ada peringkat
- HipnotisDokumen10 halamanHipnotisDwi AprianiBelum ada peringkat
- Definisi Hipotesis 1Dokumen7 halamanDefinisi Hipotesis 1You-one BestforfutureBelum ada peringkat
- Motivasi: Sebuah perjalanan ke dalam perilaku termotivasi, mulai dari studi tentang proses batin hingga teori neuropsikologis terbaruDari EverandMotivasi: Sebuah perjalanan ke dalam perilaku termotivasi, mulai dari studi tentang proses batin hingga teori neuropsikologis terbaruBelum ada peringkat
- Uraian Tugas Untuk Tiap TenagaDokumen52 halamanUraian Tugas Untuk Tiap TenagaFakhira Adzkiya SalsabilaBelum ada peringkat
- MORBIDITASDokumen43 halamanMORBIDITASFakhira Adzkiya SalsabilaBelum ada peringkat
- Kespro Dan GenderDokumen27 halamanKespro Dan GenderFakhira Adzkiya SalsabilaBelum ada peringkat
- Sasaran Vaksin 6-11 Tahun Puulemo 2022Dokumen2 halamanSasaran Vaksin 6-11 Tahun Puulemo 2022Fakhira Adzkiya SalsabilaBelum ada peringkat
- 034 Biotekonologikelautan ChindypermatasariDokumen23 halaman034 Biotekonologikelautan ChindypermatasariFakhira Adzkiya SalsabilaBelum ada peringkat
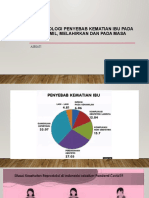
- Penyebab Kematian Ibu Saat Hamil, Melahirkan dan Masa NifasDokumen15 halamanPenyebab Kematian Ibu Saat Hamil, Melahirkan dan Masa NifasFakhira Adzkiya SalsabilaBelum ada peringkat
- TPK Konut-2Dokumen44 halamanTPK Konut-2Fakhira Adzkiya SalsabilaBelum ada peringkat
- Kel 1 - Epidemiologi Kespro Lanjut-1Dokumen39 halamanKel 1 - Epidemiologi Kespro Lanjut-1Fakhira Adzkiya SalsabilaBelum ada peringkat
- TESISDokumen139 halamanTESISFakhira Adzkiya SalsabilaBelum ada peringkat
- Makalah - Kel2 - Kesehatan - Reproduksi - RemajaDokumen30 halamanMakalah - Kel2 - Kesehatan - Reproduksi - RemajaFakhira Adzkiya SalsabilaBelum ada peringkat
- Materi 6Dokumen14 halamanMateri 6Fakhira Adzkiya SalsabilaBelum ada peringkat
- Epidemilogi KESPRODokumen41 halamanEpidemilogi KESPROFakhira Adzkiya SalsabilaBelum ada peringkat
- G121037 - Mitigasi BencanaDokumen20 halamanG121037 - Mitigasi BencanaFakhira Adzkiya SalsabilaBelum ada peringkat
- Kartu Vaksinasi Covid-19: Riwayat Pemberian Vaksin Covid-19Dokumen1 halamanKartu Vaksinasi Covid-19: Riwayat Pemberian Vaksin Covid-19Fakhira Adzkiya SalsabilaBelum ada peringkat
- EVALUASI TUGASDokumen2 halamanEVALUASI TUGASFakhira Adzkiya SalsabilaBelum ada peringkat
- Tugas Martri Wulan Kespro & GenderDokumen18 halamanTugas Martri Wulan Kespro & GenderFakhira Adzkiya SalsabilaBelum ada peringkat
- Review Artikel Kelompok 3 KemaritimanDokumen7 halamanReview Artikel Kelompok 3 KemaritimanFakhira Adzkiya SalsabilaBelum ada peringkat
- EVALUASI TUGASDokumen2 halamanEVALUASI TUGASFakhira Adzkiya SalsabilaBelum ada peringkat
- AsasDokumen108 halamanAsasFakhira Adzkiya SalsabilaBelum ada peringkat
- Ruang BersalinDokumen1 halamanRuang BersalinFakhira Adzkiya SalsabilaBelum ada peringkat
- Tesis Heni Andiaswaty (1702011150) - DikonversiDokumen166 halamanTesis Heni Andiaswaty (1702011150) - DikonversiFakhira Adzkiya SalsabilaBelum ada peringkat
- 1Dokumen4 halaman1Fakhira Adzkiya SalsabilaBelum ada peringkat
- Dupak Kel.4Dokumen53 halamanDupak Kel.4Fakhira Adzkiya SalsabilaBelum ada peringkat
- Distosia BahuDokumen12 halamanDistosia Bahuhana yulianduBelum ada peringkat
- Dupak Bidan Ahli Kel.10Dokumen8 halamanDupak Bidan Ahli Kel.10Fakhira Adzkiya SalsabilaBelum ada peringkat
- Kelompok 8 Penilaian PakDokumen14 halamanKelompok 8 Penilaian PakFakhira Adzkiya SalsabilaBelum ada peringkat
- Analisis Faktor yang Berpengaruh terhadap Tingginya Angka Rujukan di Puskesmas Pada Era JKNDokumen80 halamanAnalisis Faktor yang Berpengaruh terhadap Tingginya Angka Rujukan di Puskesmas Pada Era JKNFakhira Adzkiya SalsabilaBelum ada peringkat
- Tesis: Untuk Memenuhi Persyaratan Mencapai Derajat Sarjana S2Dokumen177 halamanTesis: Untuk Memenuhi Persyaratan Mencapai Derajat Sarjana S2Fakhira Adzkiya SalsabilaBelum ada peringkat
- 37-Article Text-190-2-10-20200229Dokumen8 halaman37-Article Text-190-2-10-20200229Muhammad FadhliBelum ada peringkat
- PERAWATAN KANGURUDokumen5 halamanPERAWATAN KANGURUFakhira Adzkiya SalsabilaBelum ada peringkat